ML-AI Python agent communication, ai, biographer agent, ChatAnthropic, Claude, conditional routing, content creation, content editing, document editing, editor agent, LangGraph, LLM, multi-agent systems, Python, specialized agents, state management, supervisor agent, task delegation, Tutorial, workflow automation Craig 0 Comments
LangGraph Multi-Agent: Hands-on with a Supervisor Agent
In the ever-evolving landscape of artificial intelligence, multi-agent systems are becoming increasingly important for handling complex tasks efficiently. The LangGraph multi-agent project exemplifies this approach, allowing different agents to specialize in various aspects of a task. This blog post explores the architecture and implementation of a multi-agent biographer that utilizes LangGraph and various AI models to create compelling biographies from research data.
If you haven’t created a LangGraph agent before we recommend you start with our article LangGraph Basics: Building Advanced AI Agents with Graph Architecture
Creating and Setting Up the LangGraph Project
To get started with the LangGraph multi-agent project, follow these setup instructions:
Set Up a Virtual Environment
Create a virtual environment to manage dependencies without interfering with your global Python installation. Open a terminal and run:
mkdir langgraph-multi-agent
cd langgraph-multi-agent
python -m venv venv
Activate the virtual environment:
- On Windows:
venv\Scripts\activate - On macOS and Linux:
source venv/bin/activate
Create pyproject.toml
Create a pyproject.toml file in the root directory with the following content:
[build-system]
requires = ["setuptools>=61.0"]
build-backend = "setuptools.build_meta"
[project]
name = "multi-agent-biographer"
version = "0.1.0"
authors = [
{name = "Your Name", email = "your.email@example.com"},
]
description = "A multi-agent LangGraph system for biography writing and editing"
readme = "README.md"
requires-python = ">=3.10"
classifiers = [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
]
dependencies = [
"langchain>=0.1.0",
"langchain-anthropic>=0.1.0",
"langgraph-cli[inmem]>=0.2.7",
"langgraph>=0.1.0",
"pydantic>=2.0.0",
"python-dotenv>=1.0.0"
]
[project.optional-dependencies]
dev = [
"pytest>=7.4.0",
"black>=23.7.0",
"isort>=5.12.0",
"mypy>=1.5.1"
]
[tool.setuptools]
package-dir = {"" = "src"}
Configure LangGraph with langgraph.json
Create a langgraph.json file in the project root to configure the LangGraph agents and their relationships:
{
"dependencies": [
"."
],
"graphs": {
"editor_agent": "./src/editor_agent/graph.py:graph",
"biographer_agent": "./src/biographer_agent/graph.py:graph",
"supervisor_agent": "./src/supervisor_agent/graph.py:graph",
"research_agent": "./src/research_agent/graph.py:graph"
},
"env": ".env"
}
Install Dependencies
Use pip to install the necessary dependencies outlined in the pyproject.toml file. Run:
pip install -e .
Create Environment Variables
Set up a .env file in the project root directory to store any sensitive information or configuration settings required by the project. You might need to include API keys for accessing language models or other services.
ANTHROPIC_API_KEY=your_anthropic_api_key_here
Create Package Structure with __init__.py Files
To make our agent modules importable, we need to create __init__.py files in each agent directory. These files are essential for Python to recognize directories as packages and allow imports between modules.
For each agent module, create the following __init__.py files:
Biographer Agent
"""Biographer agent package."""
from biographer_agent.graph import graph
__all__ = ["graph"]
Editor Agent
"""Editor agent package."""
from editor_agent.graph import graph
__all__ = ["graph"]
Research Agent
"""Research agent package."""
from research_agent.graph import graph
__all__ = ["graph"]
Supervisor Agent
"""Supervisor agent package."""
from supervisor_agent.graph import graph
__all__ = ["graph"]
The __all__ variable in each file specifies which symbols are exported when someone uses from module_name import *. In our case, we’re exporting the graph object from each agent module, which contains the compiled LangGraph workflow. This is crucial for the supervisor agent to import the specialized agent graphs.
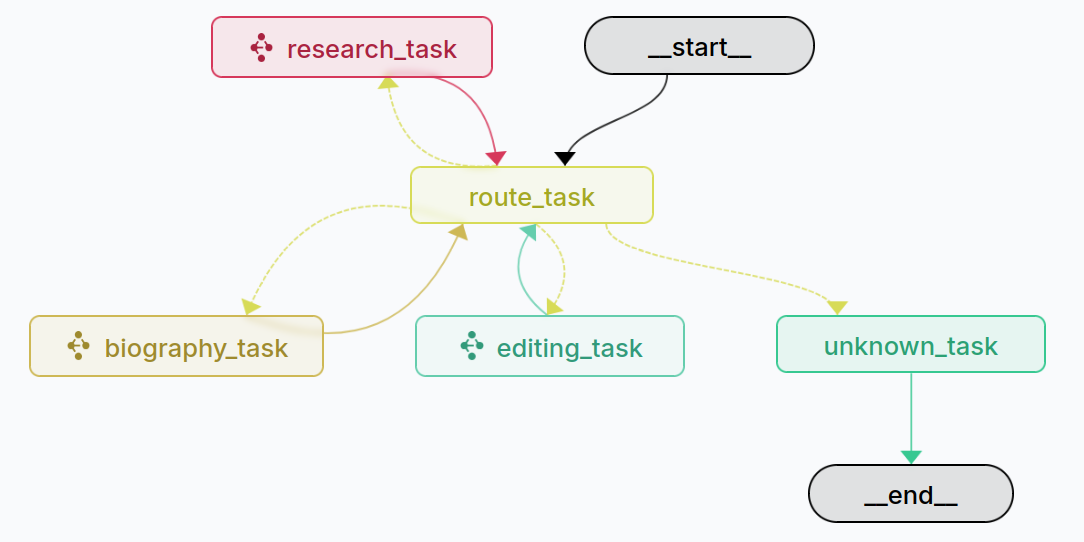
Architecture Overview
At the core of the LangGraph multi-agent system are several specialized agents, each designed to handle specific tasks. The primary agents in this project include:
- Biographer Agent: Responsible for writing engaging biographies based on research data.
- Editor Agent: Focuses on editing documents according to specific instructions.
- Research Agent: Gathers information about individuals, events, and topics.
- Supervisor Agent: Manages the workflow, routing tasks to the appropriate specialized agents based on user input.
This architecture allows for efficient collaboration between agents, ensuring that user requests are addressed promptly and accurately.
Agent Implementations
Research Agent
The research agent is responsible for gathering comprehensive information about the subjects of biographies. Below is the code implementation for the research agent:
"""Research agent graph implementation."""
from typing import Any, Dict, List, TypedDict
from langchain_anthropic import ChatAnthropic
from langgraph.graph import END, StateGraph
class ResearchState(TypedDict):
"""State for the research agent."""
# Input data
subject: str
messages: List[Dict[str, str]]
# Output data
research_data: Dict[str, Any]
def create_research_agent():
"""Create the research agent."""
model = ChatAnthropic(model="claude-3-opus-20240229")
system_prompt = """You are a research agent specialized in gathering information about people, events, and topics.
When given a subject to research:
1. Identify key aspects that should be researched (birth, education, career, achievements, etc.)
2. Simulate conducting thorough research on the subject
3. Organize the research findings into a structured format
Your output should be a comprehensive collection of facts and information about the subject,
organized in a way that would be useful for writing a biography or informational content.
Respond with a JSON object containing your research findings, structured by categories.
For example:
{
"basic_info": {
"full_name": "...",
"birth_date": "...",
"birth_place": "...",
"death_date": "..." (if applicable)
},
"early_life": {
"childhood": "...",
"education": "..."
},
"career": {
"major_roles": "...",
"achievements": "..."
},
"personal_life": {
"family": "...",
"interests": "..."
},
"legacy": {
"impact": "...",
"honors": "..."
}
}
Adapt the structure based on the specific subject being researched.
"""
return model.bind(
system=system_prompt,
)
def conduct_research(state: ResearchState):
"""Conduct research on the given subject."""
research_agent = create_research_agent()
# Prepare the prompt for the research agent
messages = state.get("messages", []).copy()
# Check if subject is provided and not empty
subject = state.get("subject", "")
if not subject:
return {
"research_data": {
"error": "No subject provided for research",
"message": "Please provide a subject to research"
},
"messages": messages
}
messages.append({
"role": "user",
"content": f"Please conduct thorough research on {subject} and provide structured information that could be used to write a biography. The subject is: {subject}"
})
# Get research results
response = research_agent.invoke(messages)
# Parse the response to extract research data
import json
import re
# Extract JSON from the response
json_match = re.search(r'```json\n(.*?)\n```', response.content, re.DOTALL)
if not json_match:
json_match = re.search(r'{.*}', response.content, re.DOTALL)
if json_match:
try:
research_data = json.loads(json_match.group(1) if '```' in response.content else json_match.group(0))
except:
# Fallback if JSON parsing fails
research_data = {
"error": "Could not parse research data",
"raw_content": response.content
}
else:
research_data = {
"error": "Could not extract structured research data",
"raw_content": response.content
}
# Update state with research data
return {
"research_data": research_data,
"messages": messages + [{"role": "assistant", "content": response.content}]
}
def create_graph():
"""Create the research agent graph."""
# Create the graph
workflow = StateGraph(ResearchState)
# Define a default state that will be used for any missing keys
default_state = {
"subject": "",
"messages": [],
"research_data": {}
}
# Add nodes
workflow.add_node("conduct_research", conduct_research)
# Define edges - return to supervisor after research
workflow.add_edge("conduct_research", END)
# Set entry point
workflow.set_entry_point("conduct_research")
return workflow
graph = create_graph().compile()
Explanation:
- The
ResearchStateclass uses TypedDict to define a strongly typed state structure for the research agent, with clear input fields (subject and messages) and output fields (research_data). For more information on LangGraph state see BaseModel vs TypedDict in LangGraph Agent State Management - The
create_research_agentfunction initializes the ChatAnthropic model with a detailed system prompt that provides clear instructions and a structured example of the expected JSON output format. - The
conduct_researchfunction has been enhanced with better error handling, including checking if a subject is provided before proceeding. It also formats the user prompt more clearly. - The JSON parsing has been improved with fallback options if the structured data can’t be extracted.
- The
create_graphfunction now includes a default state and clear edge definitions.
Biographer Agent
The biographer agent is tasked with creating biographies by synthesizing research data. It utilizes the ChatAnthropic model to generate text that is both compelling and accurate. Below is the code implementation for the biographer agent:
"""Biographer agent graph implementation."""
from typing import Annotated, Any, Dict, TypedDict
from langchain_anthropic import ChatAnthropic
from langgraph.graph import END, StateGraph
from langgraph.prebuilt import ToolNode
class BiographerState(TypedDict):
"""State for the biographer agent."""
subject: str
research_data: Dict[str, Any]
biography: str
messages: list[dict]
def create_biographer_agent():
"""Create the biographer agent."""
model = ChatAnthropic(model="claude-3-opus-20240229")
system_prompt = """You are an expert biographer. Your task is to write compelling,
accurate biographies based on research data provided to you.
Follow these guidelines:
1. Organize the biography in a clear, chronological structure
2. Focus on significant events and achievements
3. Provide context for important decisions and life events
4. Write in an engaging, narrative style
5. Maintain factual accuracy based on the research data
6. Highlight the subject's impact and legacy
Your biography should be comprehensive yet concise, capturing the essence of the
subject's life and contributions.
"""
return model.bind(
system=system_prompt,
)
def write_biography(state: BiographerState):
"""Write a biography based on research data."""
biographer = create_biographer_agent()
# Debug logging
print(f"Writing biography for: {state.get('subject', 'UNKNOWN')}")
print(f"Research data available: {bool(state.get('research_data', {}))}")
# Check if we have a valid subject
subject = state.get("subject", "")
if not subject:
return {
"biography": "I couldn't write a biography because no subject was provided.",
"messages": state["messages"]
}
# Process research data
research_data = state.get("research_data", {})
# Check if research data contains an error
if "error" in research_data:
error_msg = research_data.get("error", "Unknown error")
# If we have raw content, we can still try to use it
if "raw_content" in research_data:
research_content = f"Note: There was an issue with the structured data format, but I'll use the available information.\n\n{research_data.get('raw_content', '')}"
else:
return {
"biography": f"I couldn't write a biography because of a research error: {error_msg}. Please try again with more specific information about {subject}.",
"messages": state["messages"]
}
else:
# We have some form of research data
research_content = str(research_data)
# Prepare messages for the biographer
messages = state["messages"].copy()
messages.append({
"role": "user",
"content": f"""Write a biography for {subject} based on the following research data:
{research_content}
Create a well-structured, engaging biography that captures the essence of this person's life,
achievements, and impact. If the research data is incomplete, focus on what is known and acknowledge any gaps in information."""
})
# Get the biography from the model
response = biographer.invoke(messages)
print(f"Biography written for {subject}")
# Update state with the biography
return {
"biography": response.content,
"messages": messages + [{"role": "assistant", "content": response.content}]
}
def create_graph():
"""Create the biographer agent graph."""
workflow = StateGraph(BiographerState)
# Add nodes
workflow.add_node("write_biography", write_biography)
# Define edges - return to supervisor after writing biography
workflow.add_edge("write_biography", END)
# Set entry point
workflow.set_entry_point("write_biography")
return workflow
graph = create_graph().compile()
Explanation:
- The
BiographerStateTypedDict provides a clear type definition for the biographer agent’s state. - The
create_biographer_agentfunction sets up a ChatAnthropic model with a focused system prompt that provides specific writing guidelines. - The
write_biographyfunction has been enhanced with:- Debug logging to help with troubleshooting
- Input validation to check for a valid subject
- Error handling for research data issues, including a fallback option if structured data has an error but raw content is available
- A more detailed prompt for the biography generation
- The function returns a complete biography in the state update, along with the conversation history for potential future reference.
- The graph structure is simple but effective, with a single node that handles the biography writing task.
Editor Agent
The editor agent specializes in refining documents based on user instructions. Below is the code implementation for the editor agent:
"""Editor agent graph implementation."""
from typing import Annotated, Any, Dict, TypedDict
from langchain_anthropic import ChatAnthropic
from langgraph.graph import END, StateGraph
from langgraph.prebuilt import ToolNode
class EditorState(TypedDict):
"""State for the editor agent."""
document: str
instructions: str
edited_document: str
messages: list[dict]
def create_editor_agent():
"""Create the editor agent."""
model = ChatAnthropic(model="claude-3-opus-20240229")
system_prompt = """You are an expert editor. Your task is to edit documents
according to the instructions provided.
Follow these guidelines:
1. Carefully read the document and understand its content
2. Follow the editing instructions precisely
3. Maintain the original tone and style unless instructed otherwise
4. Ensure clarity and coherence in the edited document
5. Explain your edits when necessary
6. Be thorough but respectful of the original content
Your goal is to improve the document while respecting the author's intent.
"""
return model.bind(
system=system_prompt,
)
def edit_document(state: EditorState):
"""Edit a document based on instructions."""
editor = create_editor_agent()
messages = state["messages"].copy()
messages.append({
"role": "user",
"content": f"""Edit the following document according to these instructions:
INSTRUCTIONS:
{state['instructions']}
DOCUMENT:
{state['document']}
Please provide ONLY the edited document without any explanations or additional text.
Do not include phrases like "Here is the edited document" or any other commentary."""
})
response = editor.invoke(messages)
# Extract just the edited document from the response
edited_content = response.content.strip()
# Remove any common prefixes that might appear
prefixes_to_remove = [
"Here is the edited document:",
"Here's the edited document:",
"Edited document:",
"The edited document:"
]
for prefix in prefixes_to_remove:
if edited_content.startswith(prefix):
edited_content = edited_content[len(prefix):].strip()
# Update state with the edited document
return {
"edited_document": edited_content,
"messages": messages + [{"role": "assistant", "content": response.content}]
}
def create_graph():
"""Create the editor agent graph."""
workflow = StateGraph(EditorState)
# Add nodes
workflow.add_node("edit_document", edit_document)
# Define edges
workflow.add_edge("edit_document", END)
# Set entry point
workflow.set_entry_point("edit_document")
return workflow
graph = create_graph().compile()
Explanation:
- The
EditorStateTypedDict clearly defines what information the editor agent needs (document and instructions) and what it produces (edited_document). - The
create_editor_agentfunction creates a ChatAnthropic model with a system prompt that gives specific editing guidelines. - The
edit_documentfunction has been improved with:- A more structured prompt that clearly separates instructions from the document
- Clear instructions for the model to return only the edited document without commentary
- Post-processing logic to remove common prefixes that models sometimes add despite instructions
- The graph is focused on a single editing task, making it simple and maintainable.
Supervisor Agent
The supervisor agent plays a critical role in managing interactions between the various specialized agents. Below is the complete code implementation for the supervisor agent:
"""Supervisor agent graph implementation."""
from typing import Annotated, Any, Dict, List, Literal, TypedDict, cast
from langchain_anthropic import ChatAnthropic
from langgraph.graph import END, StateGraph
from langgraph.prebuilt import ToolNode
from biographer_agent.graph import graph as biographer_graph
from editor_agent.graph import graph as editor_graph
from research_agent.graph import graph as research_graph
class SupervisorState(TypedDict):
"""State for the supervisor agent."""
# User input and conversation history
user_input: str
conversation_history: List[Dict[str, str]]
# Task routing
task_type: Literal["biography", "editing", "unknown"]
# Research agent data
subject: str
# Biographer agent data
research_data: Dict[str, Any]
biography: str
# Editor agent data
document: str
instructions: str
edited_document: str
# Final response to user
response: str
def create_supervisor_agent():
"""Create the supervisor agent."""
model = ChatAnthropic(model="claude-3-opus-20240229")
system_prompt = """You are a helpful assistant that manages a team of specialized agents.
You have three specialized agents at your disposal:
1. Research Agent: Gathers information and research data
2. Biographer Agent: Writes biographies based on research data
3. Editor Agent: Edits documents according to specific instructions
Your task is to analyze user requests and route them to the appropriate agent.
Your job is to:
1. Understand the user's request
2. Ensure enough research data is available for the task
2. Determine which specialized agent should handle the request
3. Extract the necessary information to pass to that agent
4. Format the response from the specialized agent for the user
For research requests, extract:
- The subject (person to write about)
- Any research data provided
- Have research agent perform additional research
For biography requests, extract:
- The subject (person to write about)
- Any research data provided
- Have research agent perform additional research
- Only leverage the biographer agent if the subject is clear and research data is sufficient
- If the subject is not clear, ask the user for more information
- If the subject is clear but research data is insufficient, leverage the research agent
- If the subject is clear and research data is sufficient, leverage the biographer agent
For editing requests, extract:
- The document to be edited
- The editing instructions
Respond with a JSON object containing:
{
"task_type": "research" or "biography" or "editing" or "unknown",
"subject": "Name of person" (for research and biography tasks),
"research_data": {} (for research and biography tasks),
"document": "Text to edit" (for editing tasks),
"instructions": "Editing instructions" (for editing tasks),
"explanation": "Brief explanation of your decision"
}
"""
return model.bind(
system=system_prompt,
)
def route_task(state: SupervisorState):
"""Determine which agent should handle the task."""
supervisor = create_supervisor_agent()
# Prepare conversation history for the supervisor
# For the initial request, we just need the user input
messages = [{
"role": "user",
"content": state["user_input"]
}]
# Get supervisor's analysis
response = supervisor.invoke(messages)
# Parse the response to extract task routing information
import json
import re
# Extract JSON from the response
json_match = re.search(r'```json\n(.*?)\n```', response.content, re.DOTALL)
if not json_match:
json_match = re.search(r'{.*}', response.content, re.DOTALL)
if json_match:
try:
parsed_response = json.loads(json_match.group(1) if '```' in response.content else json_match.group(0))
except:
# Fallback if JSON parsing fails
parsed_response = {
"task_type": "unknown",
"explanation": "Could not determine the task type."
}
else:
parsed_response = {
"task_type": "unknown",
"explanation": "Could not determine the task type."
}
# Debug logging
print(f"Parsed response: {parsed_response}")
print(f"Subject detected: '{parsed_response.get('subject', 'NONE')}'")
# Update state with the routing information while preserving existing values
updated_state = {
# Preserve existing values if they exist
"biography": state.get("biography", ""),
"subject": state.get("subject", ""),
"research_data": state.get("research_data", {}),
"document": state.get("document", ""),
"instructions": state.get("instructions", ""),
"edited_document": state.get("edited_document", ""),
# Update with new values
"task_type": parsed_response.get("task_type", "unknown"),
"user_input": state["user_input"], # Preserve the original user input
"conversation_history": [{"role": "user", "content": state["user_input"]},
{"role": "assistant", "content": response.content}]
}
# Always update subject if it's in the parsed response, regardless of task type
if parsed_response.get("subject"):
updated_state["subject"] = parsed_response.get("subject")
print(f"Setting subject to: {updated_state['subject']}")
# Extract subject from user input if not found in parsed response
if not updated_state["subject"] and (parsed_response.get("task_type") == "biography" or
parsed_response.get("task_type") == "research"):
# Try to extract a name from the user input
import re
name_match = re.search(r"(?:about|for|on)\s+([A-Z][a-z]+(?:\s+[A-Z][a-z]+){0,3})", state["user_input"])
if name_match:
updated_state["subject"] = name_match.group(1)
print(f"Extracted subject from input: {updated_state['subject']}")
# Add task-specific information to the state
if parsed_response.get("task_type") in ["biography", "research"]:
# Only update research_data if it's provided and we don't already have it
if parsed_response.get("research_data") and not updated_state["research_data"]:
updated_state["research_data"] = parsed_response.get("research_data", {})
elif parsed_response.get("task_type") == "editing":
# Extract document and instructions
document = parsed_response.get("document", "")
instructions = parsed_response.get("instructions", "")
# If document is empty but we have a task_type of editing, try to extract from the user input
if not document and "edit" in state["user_input"].lower():
# Look for text in quotes or after a colon that might be the document
import re
# Try to find text in quotes first
doc_match = re.search(r"['\"](.+?)['\"]", state["user_input"])
if doc_match:
document = doc_match.group(1)
# Assume instructions are everything before the quoted text
instr_part = state["user_input"].split(doc_match.group(0))[0]
if not instructions and "make it" in instr_part:
instructions = instr_part
# If no quotes, try to find text after a colon
elif ":" in state["user_input"]:
parts = state["user_input"].split(":", 1)
if len(parts) > 1:
document = parts[1].strip()
instructions = parts[0].strip()
updated_state["document"] = document
updated_state["instructions"] = instructions
return updated_state
def route_to_next_step(state: SupervisorState) -> Literal["biography", "editing", "unknown", "research", "end"]:
"""Determine the next step based on the task type and state."""
# Debug logging
print(f"Routing next step. Task type: {state['task_type']}")
print(f"Has research data: {bool(state.get('research_data', {}))}")
print(f"Has biography: {bool(state.get('biography', ''))}")
print(f"Has edited document: {bool(state.get('edited_document', ''))}")
# If we have an edited document already, we're done
if state.get("edited_document", ""):
return "end"
# If we have a biography, send it to editing for review
elif state.get("biography", ""):
return "editing"
# If we have research data and the task is biography, go to biography task
elif state["task_type"] == "biography" and state.get("research_data", {}):
print("Routing to biography task")
return "biography"
# If we need research for a biography but don't have it yet
elif state["task_type"] == "biography" and not state.get("research_data", {}):
return "research"
# If we just completed research, go to biography
elif state["task_type"] == "research" and state.get("research_data", {}):
print("Research completed, routing to biography task")
# Update task type to biography since we're moving to that step
state["task_type"] = "biography"
return "biography"
# Otherwise follow the task type
else:
return state["task_type"]
def handle_research_task(state: SupervisorState):
"""Handle a research task using the research agent."""
# Debug logging
print(f"Research task received with subject: '{state.get('subject', 'MISSING')}'")
# Ensure we have a subject
if not state.get("subject"):
return {
"research_data": {"error": "No subject provided for research"},
"task_type": state["task_type"],
"subject": "",
"response": "I couldn't determine who to research. Please provide a specific person or topic to research."
}
# Prepare input for the research agent
research_input = {
"subject": state["subject"],
"messages": []
}
# Run the research agent
research_output = research_graph.invoke(research_input)
# Combine existing research data with new research data
combined_research_data = {**state.get("research_data", {}), **research_output["research_data"]}
print(f"Research completed for: {state['subject']}")
print(f"Research data keys: {combined_research_data.keys()}")
# If this was originally a biography task, set it back to biography
next_task_type = "biography" if state["task_type"] in ["biography", "research"] else state["task_type"]
# Update state with the combined research data and prepare for next step
return {
"research_data": combined_research_data,
# Update task type to biography if we were doing research for a biography
"task_type": next_task_type,
# Preserve the subject to ensure it's available for subsequent steps
"subject": state["subject"]
}
def handle_biography_task(state: SupervisorState):
"""Handle a biography task using the biographer agent."""
# Prepare input for the biographer agent
biographer_input = {
"subject": state["subject"],
"research_data": state["research_data"],
"messages": []
}
# Run the biographer agent
biographer_output = biographer_graph.invoke(biographer_input)
# Update state with the biography
return {
"biography": biographer_output["biography"],
"task_type": state["task_type"], # Preserve the task type
"subject": state["subject"], # Preserve the subject
"research_data": state["research_data"] # Preserve the research data
}
def handle_editing_task(state: SupervisorState):
"""Handle an editing task using the editor agent."""
# Determine which document to edit
document_to_edit = state.get("document", "")
# If no document is provided but we have a biography, use that
if not document_to_edit and state.get("biography", ""):
document_to_edit = state["biography"]
# Set default instructions for biography review if none provided
instructions = state["instructions"]
if not instructions and state.get("biography", ""):
instructions = "Review this biography for clarity, accuracy, and readability. Make any necessary improvements."
# Prepare input for the editor agent
editor_input = {
"document": document_to_edit,
"instructions": instructions,
"edited_document": "",
"messages": []
}
# Run the editor agent
editor_output = editor_graph.invoke(editor_input)
# Update state with the edited document and prepare final response
return {
"edited_document": editor_output["edited_document"],
"response": f"Here's the final document after review and editing:\n\n{editor_output['edited_document']}"
}
def handle_unknown_task(state: SupervisorState):
"""Handle tasks that don't match any specialized agent."""
return {
"response": "I'm not sure how to help with that request. I can assist with writing biographies or editing documents. Please provide more details about what you need."
}
def route_after_task(state: SupervisorState) -> Literal["end"]:
"""Route to the end after a task is complete."""
return "end"
def create_graph():
"""Create the supervisor agent graph."""
# Create the graph
workflow = StateGraph(SupervisorState)
# Define a default state that will be used for any missing keys
default_state = {
"user_input": "",
"conversation_history": [],
"task_type": "unknown",
"subject": "",
"research_data": {},
"biography": "",
"document": "",
"instructions": "",
"edited_document": "",
"response": ""
}
# Add nodes
workflow.add_node("route_task", route_task)
workflow.add_node("research_task", handle_research_task)
workflow.add_node("biography_task", handle_biography_task)
workflow.add_node("editing_task", handle_editing_task)
workflow.add_node("unknown_task", handle_unknown_task)
# Define edges for routing
workflow.add_conditional_edges(
"route_task",
route_to_next_step,
{
"biography": "biography_task",
"research": "research_task",
"editing": "editing_task",
"unknown": "unknown_task",
"end": END
}
)
# After research, route back to supervisor for next step
workflow.add_edge("research_task", "route_task")
# After biography task, route back to supervisor for editing
workflow.add_edge("biography_task", "route_task")
# After editing task, route back to supervisor for further processing
workflow.add_edge("editing_task", "route_task")
workflow.add_edge("unknown_task", END)
# Set entry point
workflow.set_entry_point("route_task")
return workflow
graph = create_graph().compile()
Explanation:
- The
SupervisorStateTypedDict provides a comprehensive definition of all possible state elements across the entire workflow, with clear sections for each agent’s data. - The
create_supervisor_agentfunction sets up a ChatAnthropic model with a detailed system prompt that covers all aspects of the supervisor’s role, including task identification, data extraction, and agent routing. - The supervisor agent implementation has been significantly enhanced with:
- Improved task routing logic that now handles a “research” task type
- Better subject extraction, including regex-based extraction from user input
- Comprehensive state management that preserves existing values while updating new ones
- Detailed debug logging to help with troubleshooting
- Advanced document and instruction extraction for editing tasks
- The
route_to_next_stepfunction has a more sophisticated decision tree that properly handles research-to-biography transitions. - The
handle_research_taskfunction now checks for a valid subject and returns a helpful error message if none is found. It also properly merges existing and new research data. - The
handle_editing_taskfunction has intelligent defaults for biography editing. - The graph structure includes proper edges for routing between agents, ensuring the workflow always returns to the supervisor for coordination.
Integrating the Multi-Agent System
Now that we’ve implemented the individual agents and the supervisor, let’s put everything together into a cohesive system.
Creating the Main Entry Point
Create a main.py file in your src directory with the following content:
from dotenv import load_dotenv
import os
from supervisor_agent.graph import graph as supervisor_graph
# Load environment variables
load_dotenv()
def process_user_request(user_input: str):
"""Process a user request through the supervisor agent."""
# Initialize the state with user input
initial_state = {
"user_input": user_input,
"conversation_history": [],
"task_type": "unknown",
"subject": "",
"research_data": {},
"biography": "",
"document": "",
"instructions": "",
"edited_document": "",
"response": ""
}
# Invoke the supervisor graph
result = supervisor_graph.invoke(initial_state)
# Return the result
return result.get("response", "No response generated.")
def main():
"""Main function to run the multi-agent system."""
print("Welcome to the Multi-Agent Biographer!")
print("You can request a biography or document editing.")
print("Type 'exit' to quit.")
while True:
user_input = input("\nWhat would you like to do? ")
if user_input.lower() == 'exit':
break
response = process_user_request(user_input)
print("\n" + response)
print("Thank you for using the Multi-Agent Biographer!")
if __name__ == "__main__":
main()
Example Usage Scenarios
Let’s walk through some example scenarios to see how our multi-agent system works in practice.
Scenario 1: Requesting a Biography
User: "Write a biography of Marie Curie"
System (Internally):
1. Supervisor analyzes the request and identifies it as a biography task for "Marie Curie"
2. Research agent is activated to gather information about Marie Curie
3. Research data is passed to the biographer agent
4. Biographer creates a biography
5. Editor automatically reviews and refines the biography
6. Final biography is presented to the user
Response:
"Here's the final document after review and editing:
Marie Skłodowska Curie (1867-1934) was a pioneering physicist and chemist whose groundbreaking work on radioactivity transformed our understanding of matter and energy. Born in Warsaw, Poland, she overcame significant gender barriers to become the first woman to win a Nobel Prize, the first person to win Nobel Prizes in two different scientific fields, and the first woman professor at the University of Paris.
[Full biography content...]"
Scenario 2: Requesting Document Editing
User: "Can you edit this paragraph to make it more concise? 'The meeting that was scheduled for tomorrow afternoon at approximately 3:00 PM has been postponed until further notice due to unforeseen circumstances that have recently come to light. All attendees who were planning to participate in the aforementioned meeting are kindly requested to await further communication regarding the rescheduling of said meeting to a future date and time that has yet to be determined.'"
System (Internally):
1. Supervisor analyzes the request and identifies it as an editing task
2. Editor agent is activated with the document and instructions
3. Editor refines the text according to the instructions
4. Edited document is presented to the user
Response:
"Here's the final document after review and editing:
'The 3:00 PM meeting scheduled for tomorrow has been postponed indefinitely due to unforeseen circumstances. Attendees should wait for information about rescheduling.'"
Testing Your Multi-Agent System
To ensure your multi-agent system is working as expected, you can create basic tests for each agent. Here’s an example test file for the biographer agent:
pip install pytest
Create an initial test:
# tests/test_biographer_agent.py
import pytest
from biographer_agent.graph import graph
def test_biographer_can_write_biography():
# Prepare test input
test_input = {
"subject": "Albert Einstein",
"research_data": {
"personal": {
"birth": "March 14, 1879, Ulm, Germany",
"death": "April 18, 1955, Princeton, New Jersey, USA",
"education": "Federal Polytechnic School in Zurich (1896-1900)"
},
"career": {
"positions": ["Patent clerk", "Professor of Physics"],
"discoveries": ["Theory of Relativity", "Photoelectric effect", "Brownian motion"]
},
"achievements": {
"awards": ["Nobel Prize in Physics (1921)"],
"publications": ["Annus Mirabilis papers (1905)"]
}
},
"messages": []
}
# Invoke the graph
result = graph.invoke(test_input)
# Check the result
assert "biography" in result
assert len(result["biography"]) > 100 # Ensure we got a substantial biography
assert "Einstein" in result["biography"] # Ensure it's about the right person
# More tests can be added here
Run the tests using pytest:
pytest tests/
For more information on testing LangGraph agents please read Testing LangGraph Agents with pytest and Test-Driven Development
Conclusion
The LangGraph multi-agent biographer project demonstrates the power of specialized AI agents working together to accomplish complex tasks. By dividing responsibilities among different agents and coordinating their work through a supervisor, we’ve created a system that can:
- Research subjects intelligently
- Write compelling biographies based on research data
- Edit and refine documents according to specific instructions
- Handle a variety of user requests seamlessly
This architecture offers several advantages:
- Modularity: Each agent can be improved or replaced independently without affecting the entire system.
- Specialization: Agents can be optimized for specific tasks rather than trying to be good at everything.
- Scalability: New specialized agents can be added to handle additional tasks as needed.
- Maintainability: The code is organized in a way that makes it easy to understand and modify.
By building on the foundation we’ve created, you can develop increasingly sophisticated multi-agent systems that leverage the power of large language models to accomplish complex tasks with greater efficiency and accuracy than single-agent approaches.
Remember, the key to successful multi-agent systems is clear communication between agents, well-defined responsibilities, and thoughtful design of the overall workflow. With these principles in mind, the possibilities for extending this system are virtually limitless.