Creating Custom Tools with CrewAI
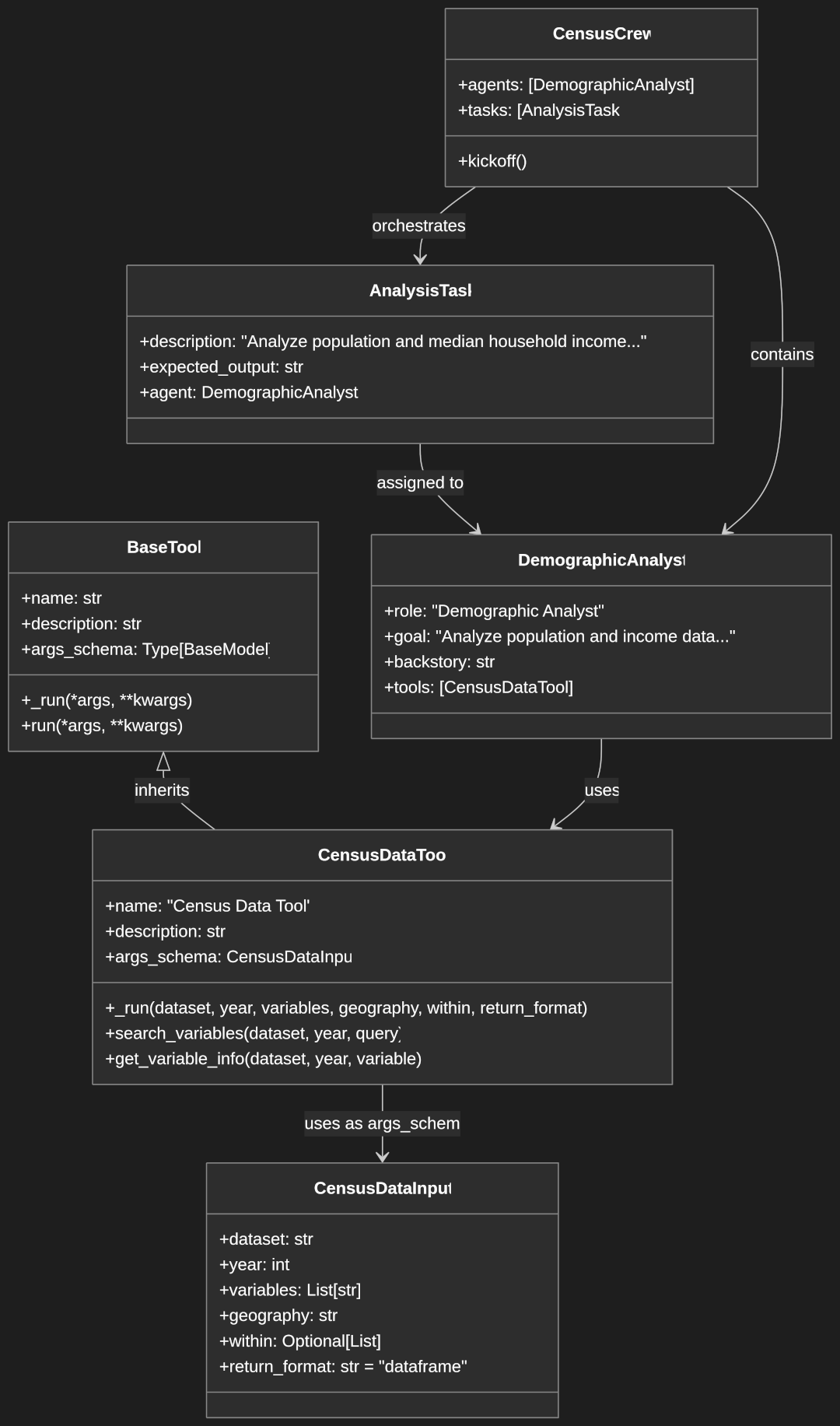
CrewAI is a framework that enables the orchestration of multiple AI agents working together to accomplish complex tasks. One of its powerful features is the ability to create custom tools that extend the capabilities of these agents. This guide will walk you through the process of creating custom tools in CrewAI, using a Census Data Tool as a practical example.
This guide assumes a knowledge of CrewAI. To get started with CrewAI read our guide on building crews with CrewAI.
Understanding CrewAI Tools
In the CrewAI framework, tools provide specialized capabilities to agents, allowing them to interact with external systems, APIs, or data sources. Custom tools can significantly enhance your agents’ abilities to solve domain-specific problems.
Anatomy of a CrewAI Custom Tool
A CrewAI custom tool consists of the following key components:
- Input Schema: A Pydantic model defining the tool’s required and optional parameters
- Tool Class: A class inheriting from
BaseToolthat implements the tool’s functionality - Tool Methods: Core logic in the
_run()method and optional helper methods
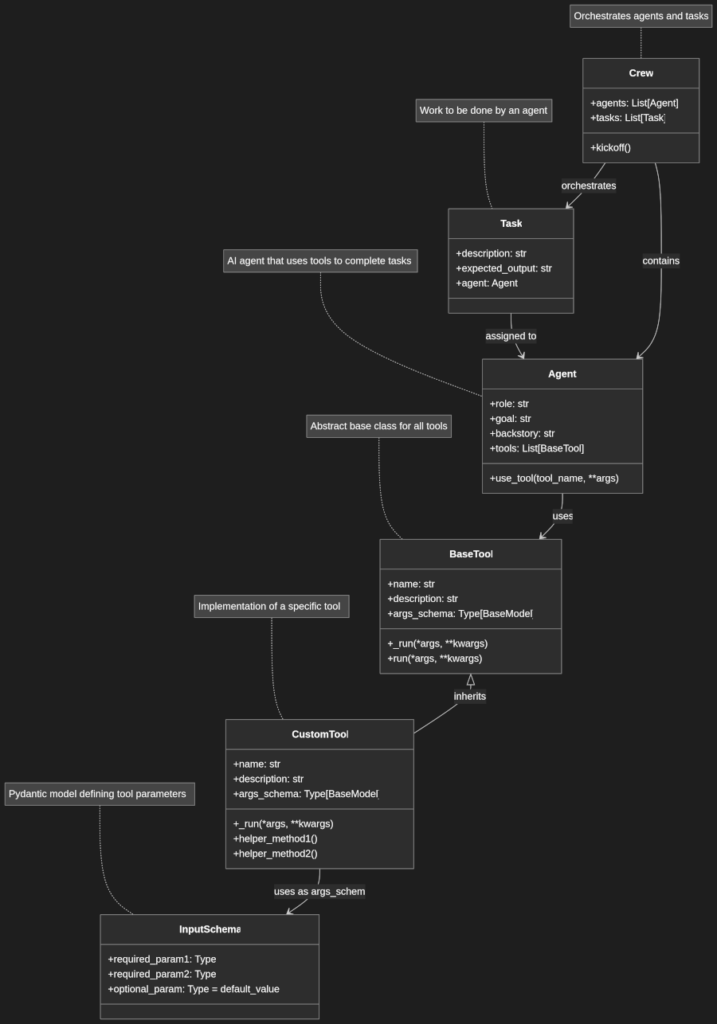
Creating a Custom Tool: Step-by-Step Guide
Let’s explore how to create a custom tool using our Census Data Tool example.
Step 1: Define the Input Schema
First, create a Pydantic model that defines the parameters your tool will accept:
class CensusDataInput(BaseModel):
"""Input schema for the Census Data Tool."""
dataset: str = Field(
...,
description="Census dataset to query (e.g., 'acs5', 'acs1', 'sf1')"
)
year: int = Field(
...,
description="Year of data to retrieve (e.g., 2019 for ACS 2015-2019 5-year estimates)"
)
variables: List[str] = Field(
...,
description="List of Census variable codes to retrieve (e.g., ['B01001_001E', 'B19013_001E'])"
)
geography: str = Field(
...,
description="Geography level (e.g., 'state', 'county', 'tract', 'block group')"
)
within: Optional[List] = Field(
None,
description="Optional geographic filter (e.g., ['state', '06'] for California)"
)
return_format: str = Field(
"dataframe",
description="Return format: 'dataframe' (default), 'dict', or 'json'"
)
- This code defines a Pydantic model called
CensusDataInputthat specifies all parameters needed for Census data retrieval. - The
Fieldclass configures each parameter with detailed descriptions and defaults:dataset: Specifies which Census Bureau dataset to query (e.g., ‘acs5’ for 5-year American Community Survey)year: The survey year, which varies by dataset (e.g., 2019 for ACS 2015-2019)variables: Census variable codes that identify specific data points (population, income, etc.)geography: The geographic level of detail for the data (states, counties, census tracts, etc.)within: Optional filter to narrow results (e.g., only counties within California)return_format: How the data should be returned to the agent for further analysis
- The
...ellipsis indicates a required field with no default value - Type annotations (
str,int, etc.) ensure appropriate data validation
Key points:
- Use descriptive field names
- Set appropriate types for each parameter
- Include detailed descriptions to help agents understand how to use the tool
- Specify default values for optional parameters
Step 2: Create the Tool Class
Next, create a class that inherits from BaseTool:
class CensusDataTool(BaseTool):
"""Tool for retrieving data from the U.S. Census Bureau's API."""
name: str = "Census Data Tool"
description: str = """
Retrieve demographic, economic, and housing data from the U.S. Census Bureau's API.
This tool can access:
- American Community Survey (ACS) 5-year estimates (2005-2009 to 2015-2019)
- ACS 1-year estimates (2012-2019)
- ACS 3-year estimates (2010-2012 to 2011-2013)
- ACS 1-year supplemental estimates (2014-2019)
- Census 2010 Summary File 1
Common datasets:
- 'acs5': ACS 5-year estimates
- 'acs1': ACS 1-year estimates
- 'acs3': ACS 3-year estimates
- 'acsse': ACS 1-year supplemental estimates
- 'sf1': 2010 Census Summary File 1
Common geographies:
- 'state': States
- 'county': Counties
- 'tract': Census tracts
- 'block group': Census block groups
- 'place': Cities, towns, and CDPs
Example variables:
- 'B01001_001E': Total population
- 'B19013_001E': Median household income
- 'B25077_001E': Median home value
"""
args_schema: Type[BaseModel] = CensusDataInput
- Our class
CensusDataToolinherits from CrewAI’sBaseTool, which provides the fundamental structure for tools. - We define three essential class attributes:
name: A concise identifier for the tool that agents can referencedescription: A comprehensive explanation of the tool’s capabilities, including available datasets, geographic levels, and example variables. This description serves as documentation for both developers and AI agents using the tool.args_schema: Links to our previously defined Pydantic model, enabling automatic validation of inputs and providing parameter documentation to agents.
- The detailed description includes examples of specific variable codes, helping agents understand how to formulate their requests.
- The class docstring provides a concise summary of the tool’s purpose.
Important elements:
- Provide a clear, concise name
- Write a comprehensive description that explains what the tool does, what data it can access, and includes examples
- Link the input schema using
args_schema
Step 3: Implement the Core Logic
The _run() method contains the main functionality of your tool:
def _run(
self,
dataset: str,
year: int,
variables: List[str],
geography: str,
within: Optional[List] = None,
return_format: str = "dataframe"
) -> Union[pd.DataFrame, Dict, str]:
"""
Run the Census Data Tool to retrieve data from the Census API.
Args:
dataset: Census dataset to query (e.g., 'acs5', 'acs1', 'sf1')
year: Year of data to retrieve
variables: List of Census variable codes to retrieve
geography: Geography level (e.g., 'state', 'county', 'tract', 'block group')
within: Optional geographic filter (e.g., ['state', '06'] for California)
return_format: Return format: 'dataframe' (default), 'dict', or 'json'
Returns:
Census data in the requested format
"""
try:
# Retrieve data from Census API
if within:
data = censusdata.download(
dataset, year,
censusdata.censusgeo([(geography, '*')] + [tuple(within)]),
variables
)
else:
data = censusdata.download(
dataset, year,
censusdata.censusgeo([(geography, '*')]),
variables
)
# Format the output as requested
if return_format == "dict":
return data.to_dict()
elif return_format == "json":
return data.to_json()
else: # Default to dataframe
return data
except Exception as e:
return f"Error retrieving Census data: {str(e)}"
- The
_run()method is the core of our tool and is automatically called by CrewAI when an agent uses the tool. - Parameter definitions match our input schema exactly to ensure consistency.
- The method leverages the
censusdataPython library to query the Census API:- First, it constructs a geographic query using
censusdata.censusgeo():- For general queries, it uses the pattern
[(geography, '*')]to get all entities of that geographic type - For filtered queries, it adds specific constraints like
[('state', '06')]to limit to California
- For general queries, it uses the pattern
- Then it calls
censusdata.download()to retrieve the specified variables
- First, it constructs a geographic query using
- The method handles different output formats:
dataframe: Returns a pandas DataFrame (default)dict: Converts the DataFrame to a Python dictionaryjson: Converts the DataFrame to a JSON string
- Error handling with try/except ensures the agent receives helpful error messages rather than crashing
- Return type annotation
Union[pd.DataFrame, Dict, str]documents the possible return types
Best practices for the _run() method:
- Match the parameters with your input schema
- Include comprehensive documentation
- Implement error handling
- Return data in a format that agents can easily process
Step 4: Add Helper Methods (Optional)
You can add additional methods to provide supplementary functionality:
def search_variables(self, dataset: str, year: int, query: str) -> pd.DataFrame:
"""
Search for Census variables matching a query.
Args:
dataset: Census dataset to search in (e.g., 'acs5')
year: Year to search in
query: Search term
Returns:
DataFrame of matching variables
"""
try:
return censusdata.search(dataset, year, query)
except Exception as e:
return f"Error searching Census variables: {str(e)}"
def get_variable_info(self, dataset: str, year: int, variable: str) -> Dict:
"""
Get detailed information about a specific Census variable.
Args:
dataset: Census dataset (e.g., 'acs5')
year: Year
variable: Variable code or table ID
Returns:
Dictionary with variable information
"""
try:
return censusdata.censusvar(dataset, year, variable)
except Exception as e:
return f"Error getting variable info: {str(e)}"
- These helper methods extend the core functionality of our tool:
search_variables(): Helps agents find relevant Census variables by searching keywords (like “income” or “population”)get_variable_info(): Provides metadata about specific variables, helping agents understand what the data represents
- Both methods pass queries directly to the corresponding
censusdatalibrary functions - Each includes proper error handling with try/except blocks
- The methods follow the same documentation pattern as
_run()with clear parameter explanations and return value descriptions - These helper methods don’t replace the core
_run()functionality but complement it by helping agents prepare better queries
Integrating Your Custom Tool with CrewAI
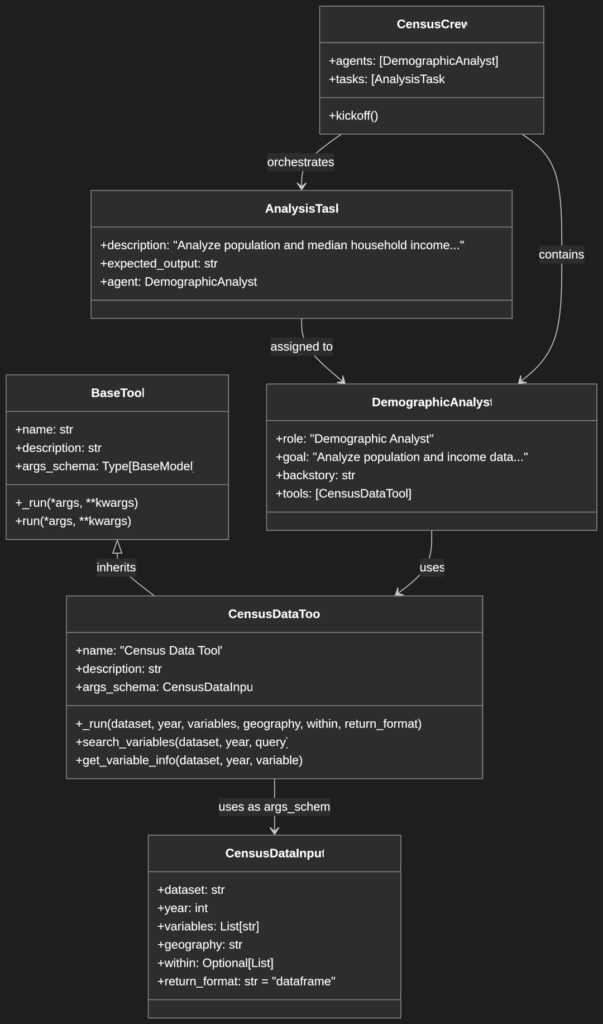
Once you’ve created your tool, here’s how to use it with CrewAI agents:
Step 1: Import and Initialize Your Tool
from crewai import Agent, Task, Crew
from census_data_tool import CensusDataTool
# Initialize the Census Data Tool
census_tool = CensusDataTool()
- We import the necessary classes from the CrewAI framework (
Agent,Task,Crew) - We import our custom tool class (
CensusDataTool) - We create an instance of our tool (
census_tool), which we’ll pass to our agent - No parameters are needed for initialization in this example, but you could add configuration parameters if necessary (like API keys)
Step 2: Create an Agent with Your Tool
demographic_analyst = Agent(
role="Demographic Analyst",
goal="Analyze population and income data for California counties",
backstory="""You are an expert demographic analyst specializing in U.S. Census data.
Your expertise helps organizations understand population trends and economic indicators
across different geographic areas.""",
verbose=True,
tools=[census_tool]
)
- We create a specialized agent with demographic analysis expertise
- The agent configuration includes:
role: Defines the agent’s professional identity, guiding its approach to tasksgoal: Specifies what the agent aims to achieve, focusing its actions on California demographic analysisbackstory: Provides context and expertise background that shapes how the agent interprets and analyzes dataverbose: When set to True, the agent will provide detailed logs of its thinking processtools: A list containing our census_tool instance, giving the agent access to Census data
- The agent now has access to all the functionality we defined in our custom tool
- Each agent can have multiple tools, allowing for combinations of different capabilities
Step 3: Create Tasks for Your Agent
analysis_task = Task(
description="""
Analyze the population and median household income for all counties in California.
1. Retrieve total population (B01001_001E) and median household income (B19013_001E)
for all counties in California using the most recent ACS 5-year data.
2. Identify the three counties with the highest and lowest median household incomes.
3. Calculate the average median household income across all counties.
4. Provide insights on the relationship between population size and median income.
Present your findings in a clear, organized format with relevant statistics.
""",
expected_output="""A comprehensive analysis of California counties including population data,
median household income statistics, rankings of counties by income, and insights on population-income relationships.""",
agent=demographic_analyst
)
- The task defines a specific analysis problem for our agent to solve using the Census Data Tool
- The
descriptionparameter provides detailed instructions:- It specifies exact Census variable codes (B01001_001E, B19013_001E) the agent should use
- It outlines a step-by-step analytical process (retrieving data, identifying extremes, calculating averages, analyzing relationships)
- It includes formatting requirements for the final output
- The
expected_outputparameter clarifies what successful completion looks like - The
agentparameter assigns this task to our demographic_analyst agent - The task instructions are designed to leverage the capabilities of our custom Census Data Tool:
- Retrieving specific variables
- Filtering for California counties
- Performing analysis on the returned data
Step 4: Create and Run the Crew
census_crew = Crew(
agents=[demographic_analyst],
tasks=[analysis_task],
verbose=True
)
result = census_crew.kickoff()
print("\nFinal Result:")
print(result)
- We create a
Crewinstance, which orchestrates the execution of tasks by agents - The crew configuration includes:
agents: A list of all agents participating in the crew (in this case, just our demographic_analyst)tasks: A list of all tasks to be completed (our analysis_task)verbose: When True, provides detailed logs of crew operations and agent interactions
- The
kickoff()method starts the execution process:- The crew evaluates all tasks and assigns them to appropriate agents
- Our demographic_analyst receives the analysis_task
- The agent uses the Census Data Tool to retrieve the required data
- The agent performs the requested analysis
- The results are returned as the output of the
kickoff()method
- Finally, we print the analysis results
Best Practices for Custom Tool Development
- Documentation is Key: Provide comprehensive descriptions for your tool, its parameters, and methods
- Error Handling: Implement robust error handling to prevent agent workflows from breaking
- Clear Return Values: Return data in formats that are easy for agents to process
- Focused Functionality: Design tools to do one thing well, rather than trying to cover too many use cases
- Testing: Test your tool thoroughly with various inputs to ensure it behaves as expected
- Type Hinting: Use proper type annotations to make your code more maintainable
Conclusion
Creating custom tools for CrewAI allows you to significantly extend the capabilities of your AI agents. By following the structure outlined in this guide and referencing the Census Data Tool example, you can develop powerful tools that enable your agents to interact with specialized data sources and APIs, making your CrewAI implementations more versatile and effective.