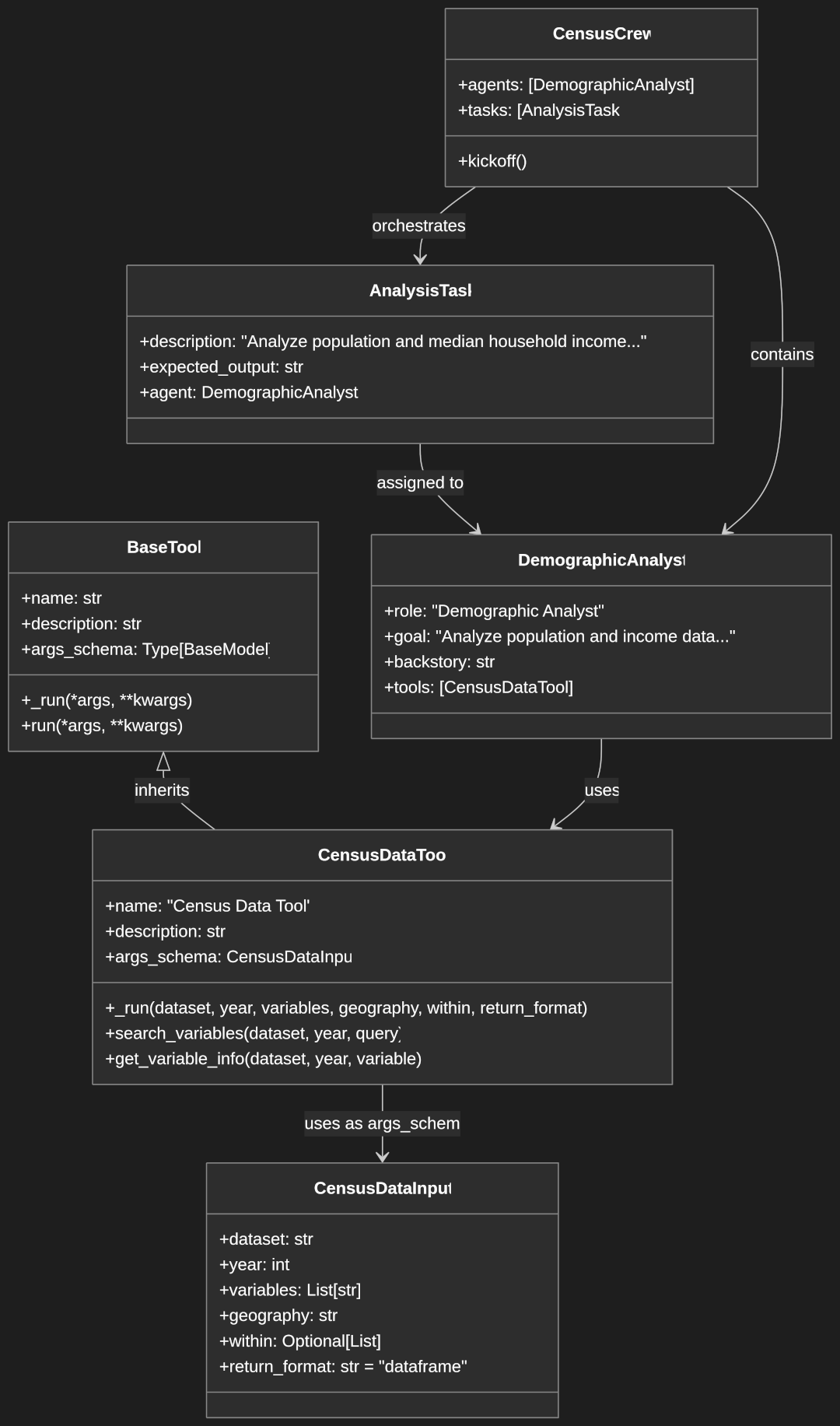
Using Flask with Marshmallow: Building a Blog API
Flask-Marshmallow is a powerful extension that brings together Flask, a popular Python web framework, and Marshmallow, a sophisticated object serialization/deserialization library. Instead of just explaining the concepts, let’s build a practical blog API application together that will demonstrate these concepts in action. If you’re new to Flask read our Getting Started with Flask APIs guide.
What We’ll Build
We’ll create a RESTful Blog API where:
- Users can register and create profiles
- Users can create, edit, and delete blog posts
- Posts can have tags for categorization
- The API will handle serialization, validation, and relationships
Project Setup
Let’s start by setting up our project:
# Create project directory
mkdir flask-marshmallow-blog
cd flask-marshmallow-blog
# Create virtual environment
python3 -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
# Install dependencies
pip install flask flask-sqlalchemy flask-marshmallow marshmallow-sqlalchemy
These commands create our project directory, set up a Python virtual environment, and install our required dependencies.
Create a basic folder structure:
mkdir -p app/{models,routes,schemas}
touch app/__init__.py app/models/__init__.py app/routes/__init__.py app/schemas/__init__.py
touch config.py run.py
This sets up our application structure following a blueprint pattern with separate directories for models, routes, and schemas.
Setting Up Our Application
First, let’s create our Flask application with SQLAlchemy and Marshmallow configurations:
# app/__init__.py
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from flask_marshmallow import Marshmallow
# Initialize extensions
db = SQLAlchemy()
ma = Marshmallow()
def create_app(config_object="config.DevelopmentConfig"):
app = Flask(__name__)
app.config.from_object(config_object)
# Initialize extensions with app
db.init_app(app)
ma.init_app(app)
# Register blueprints
from app.routes.api import api_bp
app.register_blueprint(api_bp)
return app
This is our application factory pattern. We initialize our extensions outside the function and then bind them to the Flask app inside the create_app function. This pattern allows for easier testing and more flexible configuration.
Now let’s set up our configuration:
# config.py
import os
class Config:
SECRET_KEY = os.environ.get('SECRET_KEY', 'dev-key-for-demo')
SQLALCHEMY_TRACK_MODIFICATIONS = False
class DevelopmentConfig(Config):
DEBUG = True
SQLALCHEMY_DATABASE_URI = 'sqlite:///blog.db'
class TestingConfig(Config):
TESTING = True
SQLALCHEMY_DATABASE_URI = 'sqlite:///test.db'
This configuration file defines different settings for development and testing environments. Using classes for configuration makes it easy to switch between environments.
Create our entry point:
# run.py
from app import create_app, db
app = create_app()
if __name__ == '__main__':
with app.app_context():
db.create_all()
app.run(debug=True)
This script creates our application and initializes the database when run directly. The with app.app_context() ensures database operations happen within the application context.
Building Our Data Models
Let’s create our SQLAlchemy models for our blog application:
from app.models.user import User
from app.models.post import Post
from app.models.tag import Tag
This imports all our models so they can be easily imported elsewhere using from app.models import User, Post, Tag.
Create the user model:
# app/models/user.py
from datetime import datetime
from app import db
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True, nullable=False)
email = db.Column(db.String(120), unique=True, nullable=False)
created_at = db.Column(db.DateTime, default=datetime.utcnow)
posts = db.relationship('Post', backref='author', lazy=True, cascade='all, delete-orphan')
def __repr__(self):
return f'<User {self.username}>'
This is our User model with fields for username, email, and creation time. The relationship with Post is defined using db.relationship, and cascade='all, delete-orphan' ensures posts are deleted when a user is deleted.
Create the post and tag models:
# app/models/post.py
from datetime import datetime
from app import db
# Post and Tag association table for many-to-many relationship
post_tags = db.Table('post_tags',
db.Column('post_id', db.Integer, db.ForeignKey('post.id'), primary_key=True),
db.Column('tag_id', db.Integer, db.ForeignKey('tag.id'), primary_key=True)
)
class Post(db.Model):
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String(100), nullable=False)
content = db.Column(db.Text, nullable=False)
created_at = db.Column(db.DateTime, default=datetime.utcnow)
updated_at = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
user_id = db.Column(db.Integer, db.ForeignKey('user.id'), nullable=False)
tags = db.relationship('Tag', secondary=post_tags, lazy='subquery',
backref=db.backref('posts', lazy=True))
def __repr__(self):
return f'<Post {self.title}>'
The Post model includes the association table post_tags to handle the many-to-many relationship with Tags. The updated_at field automatically updates whenever the post is modified thanks to the onupdate parameter.
# app/models/tag.py
from app import db
class Tag(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(50), unique=True, nullable=False)
def __repr__(self):
return f'<Tag {self.name}>'
The Tag model is simple, storing just an ID and name. The relationship with posts is handled by the association table defined in the Post model.
Creating Marshmallow Schemas
Marshmallow schemas are essential for converting complex Python objects (like our SQLAlchemy models) to and from simple Python types that can be rendered to JSON. Let’s create our schemas one by one and understand what each part does.
User Schema
First, let’s create the schema for our User model:
# app/schemas/user.py
from app import ma
from app.models.user import User
from marshmallow import fields, validates, ValidationError
class UserSchema(ma.SQLAlchemySchema):
class Meta:
model = User
load_instance = True # Optional: deserialize to model instances
id = ma.auto_field(dump_only=True)
username = ma.auto_field(required=True)
email = ma.auto_field(required=True)
created_at = ma.auto_field(dump_only=True)
posts = fields.Nested('PostSchema', many=True, exclude=('author',), dump_only=True)
@validates('username')
def validate_username(self, username, **kwargs):
if len(username) < 3:
raise ValidationError("Username must be at least 3 characters long.")
context = getattr(self, 'context', {})
if not context.get('user_id') and User.query.filter_by(username=username).first():
raise ValidationError("Username already exists.")
This schema defines how User objects are converted to/from JSON. It links to the User model and specifies load_instance=True to create model instances directly when deserializing. Fields are defined using auto_field() with appropriate options: dump_only=True for read-only fields and required=True for mandatory fields. The schema handles the one-to-many relationship with posts through a nested field, excluding the author field to prevent circular references.
The @validates decorator provides custom validation for usernames, checking minimum length and uniqueness. The validation method uses getattr(self, 'context', {}) to safely access the context dictionary, handling cases where context isn’t available.
Post Schema
Next, let’s create the schema for our Post model:
# app/schemas/post.py
from app import ma
from app.models.post import Post
from marshmallow import fields, validates_schema, ValidationError
class PostSchema(ma.SQLAlchemySchema):
class Meta:
model = Post
load_instance = True
id = ma.auto_field(dump_only=True)
title = ma.auto_field(required=True)
content = ma.auto_field(required=True)
created_at = ma.auto_field(dump_only=True)
updated_at = ma.auto_field(dump_only=True)
user_id = ma.auto_field(load_only=True)
author = fields.Nested('UserSchema', only=('id', 'username'), dump_only=True)
tags = fields.Nested('TagSchema', many=True, only=('id', 'name'))
@validates_schema
def validate_title_content(self, data, **kwargs):
if data.get('title') == data.get('content'):
raise ValidationError("Title and content should be different.")
The PostSchema introduces:
fields.Nestedfor representing relationships between modelsonly=()parameter to selectively include fields from related schemasload_only=Truefor fields like user_id that should be processed on input but not returned in output- Schema-level validation with
@validates_schemato compare multiple fields
Tag Schema
Now, let’s create the schema for our Tag model:
# app/schemas/tag.py
from app import ma
from app.models.tag import Tag
class TagSchema(ma.SQLAlchemySchema):
class Meta:
model = Tag
load_instance = True
id = ma.auto_field(dump_only=True)
name = ma.auto_field(required=True)
The TagSchema is intentionally simple since tags only have two fields. This minimalist approach is often appropriate for simpler models.
Creating Schema Instances
Finally, we’ll create instances of our schemas in the schemas package’s __init__.py file:
# app/schemas/__init__.py
from app.schemas.user import UserSchema
from app.schemas.post import PostSchema
from app.schemas.tag import TagSchema
# Create instances for both single objects and collections
user_schema = UserSchema()
users_schema = UserSchema(many=True)
post_schema = PostSchema()
posts_schema = PostSchema(many=True)
tag_schema = TagSchema()
tags_schema = TagSchema(many=True)
By creating these instances in the __init__.py file:
- We separate instance creation from class definition
- We prepare separate schemas for single objects and collections (
many=True) - We make them easily importable throughout the application
These schemas will allow us to:
- Convert SQLAlchemy models to JSON for API responses
- Validate and convert incoming JSON data to SQLAlchemy models
- Handle nested relationships between models
- Apply custom validation rules to enforce data quality
This approach keeps our data handling logic separate from our API routes, making the code more maintainable and easier to test.
Building API Routes
Now, let’s implement our API routes:
# app/routes/api.py
from flask import Blueprint, request, jsonify
from marshmallow import ValidationError
from app import db
from app.models.user import User
from app.models.post import Post
from app.models.tag import Tag
from app.schemas import user_schema, users_schema, post_schema, posts_schema, tag_schema, tags_schema
api_bp = Blueprint('api', __name__, url_prefix='/api')
# Error handling
@api_bp.errorhandler(ValidationError)
def handle_validation_error(err):
return jsonify({"status": "error", "message": err.messages}), 400
# User routes
@api_bp.route('/users', methods=['GET'])
def get_users():
users = User.query.all()
return jsonify(users_schema.dump(users))
@api_bp.route('/users/<int:user_id>', methods=['GET'])
def get_user(user_id):
user = User.query.get_or_404(user_id)
return jsonify(user_schema.dump(user))
@api_bp.route('/users', methods=['POST'])
def create_user():
try:
user = user_schema.load(request.json)
db.session.add(user)
db.session.commit()
return jsonify(user_schema.dump(user)), 201
except ValidationError as err:
return jsonify({"errors": err.messages}), 422
# Post routes
@api_bp.route('/posts', methods=['GET'])
def get_posts():
posts = Post.query.all()
return jsonify(posts_schema.dump(posts))
@api_bp.route('/posts/<int:post_id>', methods=['GET'])
def get_post(post_id):
post = Post.query.get_or_404(post_id)
return jsonify(post_schema.dump(post))
@api_bp.route('/posts', methods=['POST'])
def create_post():
try:
# Extract tag data if provided
json_data = request.json
tag_names = json_data.pop('tag_names', [])
# Create post
post = post_schema.load(json_data)
# Process tags
for tag_name in tag_names:
tag = Tag.query.filter_by(name=tag_name).first()
if not tag:
tag = Tag(name=tag_name)
db.session.add(tag)
post.tags.append(tag)
db.session.add(post)
db.session.commit()
return jsonify(post_schema.dump(post)), 201
except ValidationError as err:
return jsonify({"errors": err.messages}), 422
This routes file demonstrates:
- Using Flask’s Blueprint for organizing routes
- Custom error handling for validation errors
- GET endpoints for retrieving users and posts
- POST endpoints that use our schemas to validate and convert input data
- Special handling for tag relationships in the create_post function
- Proper HTTP status codes (201 for creation, 422 for validation errors)
Using Our API
Now let’s test our API to demonstrate how it works:
- First, start the application:
python run.py
This command runs our Flask application, creating the database tables if they don’t exist.
- Create a new user:
# Command to run in your terminal
curl -X POST -H "Content-Type: application/json" -d '{
"username": "johndoe",
"email": "john@example.com"
}' http://localhost:5000/api/users
This curl command sends a POST request to create a user. Our UserSchema validates the input and converts it to a User object.
Expected response:
{
"id": 1,
"username": "johndoe",
"email": "john@example.com",
"created_at": "2023-02-25T14:30:45.123456",
"posts": []
}
The response shows our schema in action, automatically including the generated ID, creation time, and empty posts array.
- Create a blog post with tags:
# Command to run in your terminal
curl -X POST -H "Content-Type: application/json" -d '{
"title": "Getting Started with Flask and Marshmallow",
"content": "This is my first post about Flask and Marshmallow integration...",
"user_id": 1,
"tag_names": ["Flask", "Marshmallow", "Python"]
}' http://localhost:5000/api/posts
This request creates a post and associates it with tags. Note how we handle the tag creation in our route function.
Expected response:
{
"id": 1,
"title": "Getting Started with Flask and Marshmallow",
"content": "This is my first post about Flask and Marshmallow integration...",
"created_at": "2023-02-25T14:35:22.123456",
"updated_at": "2023-02-25T14:35:22.123456",
"author": {
"id": 1,
"username": "johndoe"
},
"tags": [
{"id": 1, "name": "Flask"},
{"id": 2, "name": "Marshmallow"},
{"id": 3, "name": "Python"}
]
}
The response shows nested serialization at work – both the author and tags relationships are properly handled.
- Fetch all posts:
curl http://localhost:5000/api/posts
This command retrieves all posts with their relationships properly serialized.
Common Operations with Marshmallow
Let’s look at how we used Marshmallow in our blog application:
Serialization (Dumping)
We saw this in action in our routes when we converted our database models to JSON:
# Single object serialization
@api_bp.route('/users/<int:user_id>', methods=['GET'])
def get_user(user_id):
user = User.query.get_or_404(user_id)
return jsonify(user_schema.dump(user))
# Multiple objects serialization
@api_bp.route('/users', methods=['GET'])
def get_users():
users = User.query.all()
return jsonify(users_schema.dump(users))
The dump() method transforms our SQLAlchemy models into Python dictionaries that can be easily converted to JSON. For collections, we use the schema instantiated with many=True.
Deserialization (Loading)
When we create new resources, we convert incoming JSON to model instances:
# Create user example
@api_bp.route('/users', methods=['POST'])
def create_user():
try:
user = user_schema.load(request.json) # Convert JSON to User instance
db.session.add(user)
db.session.commit()
return jsonify(user_schema.dump(user)), 201
except ValidationError as err:
return jsonify({"errors": err.messages}), 422
The load() method validates the input data and creates a User instance because we set load_instance=True in our schema. Any validation errors are caught and returned as a 422 response.
Validation
Our schemas automatically validate incoming data based on the field definitions:
# In UserSchema
@validates('username')
def validate_username(self, username):
if len(username) < 3:
raise ValidationError("Username must be at least 3 characters long.")
# filepath: app/schemas/post.py (excerpt)
# In PostSchema
@validates_schema
def validate_title_content(self, data, **kwargs):
if data.get('title') == data.get('content'):
raise ValidationError("Title and content should be different.")
Validation can happen at the field level with @validates or at the schema level with @validates_schema when you need to compare multiple fields.
Handling Relationships
We’ve handled one-to-many and many-to-many relationships in our schemas:
# One-to-many: User to Posts
class UserSchema(ma.SQLAlchemySchema):
# ...
posts = fields.Nested('PostSchema', many=True, exclude=('author',), dump_only=True)
# filepath: app/schemas/post.py (excerpt)
# Many-to-many: Posts to Tags
class PostSchema(ma.SQLAlchemySchema):
# ...
tags = fields.Nested('TagSchema', many=True, only=('id', 'name'))
The fields.Nested type handles relationships. Parameters like exclude and only help prevent circular references and limit which fields are included.
Conclusion
In this hands-on guide, we’ve built a fully functional blog API using Flask and Marshmallow. We’ve seen how:
- Flask-Marshmallow simplifies the process of serializing/deserializing SQLAlchemy models
- Schemas provide powerful validation capabilities
- Relationships can be easily represented and managed
- The separation of concerns makes our code more maintainable