Using TensorFlow.js ML Models for Pose Detection in the Browser
Machine learning has traditionally required specialized knowledge and powerful servers, but TensorFlow.js now brings these capabilities directly to web browsers. By leveraging TensorFlow.js pretrained models we can quickly perform a variety of machine learning tasks.
Browser-based machine learning offers several compelling advantages:
- Enhanced Privacy: User data never leaves their device
- Reduced Server Load: Client-side processing reduces infrastructure costs
- Offline Capabilities: Applications function without an internet connection
- Lower Latency: Eliminating network round-trips creates more responsive experiences
In this tutorial, we’ll build a real-time gesture control application that uses your webcam to detect body poses and respond to specific movements. Our application will:
- Access the webcam feed
- Process video frames using TensorFlow.js and the MoveNet model
- Detect 17 key body points (shoulders, wrists, knees, etc.)
- Recognize specific gestures based on keypoint relationships
- Control an on-screen element using these detected gestures
By the end of this tutorial, you’ll have an interactive application that responds to physical movements—similar to systems like Microsoft Kinect, but running entirely in a web browser without additional hardware. Final source code is available on GitHub.

TensorFlow.js Overview
TensorFlow.js is an open-source JavaScript library developed by Google that brings machine learning to browsers and Node.js. It leverages WebGL for GPU-accelerated computations, enabling complex ML operations to run efficiently on most modern devices.
For our pose detection system, we’ll use MoveNet, a model that balances speed and accuracy. This pre-trained model identifies key body points and works at interactive frame rates even on mobile devices, making it ideal for our gesture control application.
Pre-trained Models in TensorFlow.js
One of TensorFlow.js’s greatest strengths is its ecosystem of pre-trained models, which allow developers to implement sophisticated ML capabilities without needing to train models from scratch. The TensorFlow.js team provides a collection of ready-to-use models covering various domains, including image classification, object detection, natural language processing, and human pose estimation.
For our application, we’ll focus on MoveNet, a pose detection model that:
- Identifies 17 key body points (nose, eyes, ears, shoulders, elbows, wrists, hips, knees, and ankles)
- Runs at interactive frame rates even on mobile devices
- Maintains high accuracy while requiring minimal computational resources
Alternative models like PoseNet (the predecessor to MoveNet) and BlazePose (optimized for upper body detection) are also available. We’ve selected MoveNet because it offers the best balance of speed and accuracy for full-body gesture control applications, making it ideal for our interactive use case.
Project Setup and Prerequisites
Before we begin, ensure you have:
- Node.js (version 14 or later)
- A recent web browser with webcam access
- Basic familiarity with React and TypeScript
Let’s start building our pose detection application!
Building Our Pose Detection Application
Project Setup
We’ll start by creating a new project using Vite, a build tool with features like fast hot module replacement and optimized builds. Select React and Typescript when running npm create vite@latest tfjs-pose-detection-app.
Let’s create our project:
npm create vite@latest tfjs-pose-detection-app
cd tfjs-pose-detection-app
npm install
npm run devWhen creating the project select React for the framework and Typescript for the variant. After running these commands, you’ll have a basic React application running at http://localhost:5173 (or another port if 5173 is in use). Vite automatically sets up a development server with hot module replacement, so changes to your code will be reflected immediately in the browser.
Installing Dependencies
Now that we have our basic project structure, we need to add TensorFlow.js and related libraries. We have two options for including TensorFlow.js in our project:
- Via CDN (using script tags):
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@latest/dist/tf.min.js"></script>
- Via npm (recommended for production applications):
npm install @tensorflow/tfjs
npm install @tensorflow-models/pose-detectionFor our project, we’ll use the npm approach. In addition to the core TensorFlow.js library, we need the pose detection model package. This package contains several pre-trained models for human pose detection, including MoveNet, which we’ll be using in this tutorial.
Creating the Core Components
Before we dive into code, let’s understand the architecture of our application and create the necessary folder structure.
Application Architecture Overview
Our application will follow a component-based architecture with clear separation of concerns:
- Webcam Component: Handles camera access and video streaming
- Pose Detection Hook: Manages the TensorFlow.js model and pose detection
- Canvas Component: Visualizes the detected pose keypoints and skeleton
- Gesture Detection Utilities: Analyzes keypoints to recognize specific gestures
- Gesture-controlled Interface: Responds to detected gestures
Let’s create the necessary folder structure:
mkdir -p src/{components,hooks,utils}The components folder will contain React components, hooks will contain custom React hooks for stateful logic, and utils will house helper functions for pose and gesture detection.
Setting Up the Webcam Component
The first step in our pose detection pipeline is accessing the user’s webcam feed. We’ll create a reusable WebcamComponent that:
- Requests access to the user’s webcam
- Creates a video stream that can be processed by TensorFlow.js
- Handles cleanup when the component unmounts
src/components/WebcamComponent.tsx:
import { useEffect, useRef, useState } from 'react';
interface WebcamComponentProps {
onVideoReady: (video: HTMLVideoElement) => void;
width?: number;
height?: number;
}
export const WebcamComponent = ({ onVideoReady, width = 640, height = 480 }: WebcamComponentProps) => {
const videoRef = useRef<HTMLVideoElement>(null);
const [isInitialized, setIsInitialized] = useState(false);
useEffect(() => {
if (isInitialized) return;
const enableWebcam = async () => {
if (videoRef.current) {
const video = videoRef.current;
try {
const stream = await navigator.mediaDevices.getUserMedia({
video: { width, height }
});
video.srcObject = stream;
video.addEventListener('loadeddata', () => {
if (video.readyState === 4) {
// Video is ready to be processed
onVideoReady(video);
}
});
} catch (error) {
console.error('Error accessing webcam:', error);
}
}
};
enableWebcam();
setIsInitialized(true);
return () => {
// Cleanup: stop all video tracks when component unmounts
if (videoRef.current && videoRef.current.srcObject) {
const stream = videoRef.current.srcObject as MediaStream;
stream.getTracks().forEach(track => {
track.stop();
stream.removeTrack(track);
});
videoRef.current.srcObject = null;
}
};
}, []); // Empty dependency array since we manage initialization with state
return (
<video
ref={videoRef}
autoPlay
playsInline
muted
width={width}
height={height}
style={{ transform: 'scaleX(-1)' }} // Mirror the webcam
/>
);
};
Let’s break down this component:
- Props Interface: We define
WebcamComponentPropsto specify the component’s API:onVideoReady: A callback function that receives the video element once it’s ready for processingwidthandheight: Optional dimensions for the video feed (defaulting to 640×480)
- State and Refs:
videoRef: A reference to the HTML video elementisInitialized: A state variable to track whether we’ve already attempted to initialize the webcam
- Webcam Initialization:
- We use
navigator.mediaDevices.getUserMedia()to request camera access - Specify our desired video dimensions
- Handle permissions errors
- We use
- Video Ready Event:
- We listen for the
loadeddataevent to know when the video is ready - We check
readyState === 4to ensure the video is fully loaded - Once ready, we call the
onVideoReadycallback to notify the parent component
- We listen for the
- Cleanup:
- When the component unmounts, we stop all video tracks
- We remove tracks from the stream and clear the
srcObject - This ensures we don’t leave the camera active when not in use
- Video Mirroring:
- We apply
transform: scaleX(-1)to flip the video horizontally - This creates a more intuitive “mirror” experience for users
- We apply
The WebcamComponent is designed to be reusable and handle all the browser-specific complexities of accessing a user’s camera. By separating this functionality, we can focus on the pose detection logic in other components.
Integrating the MoveNet Model
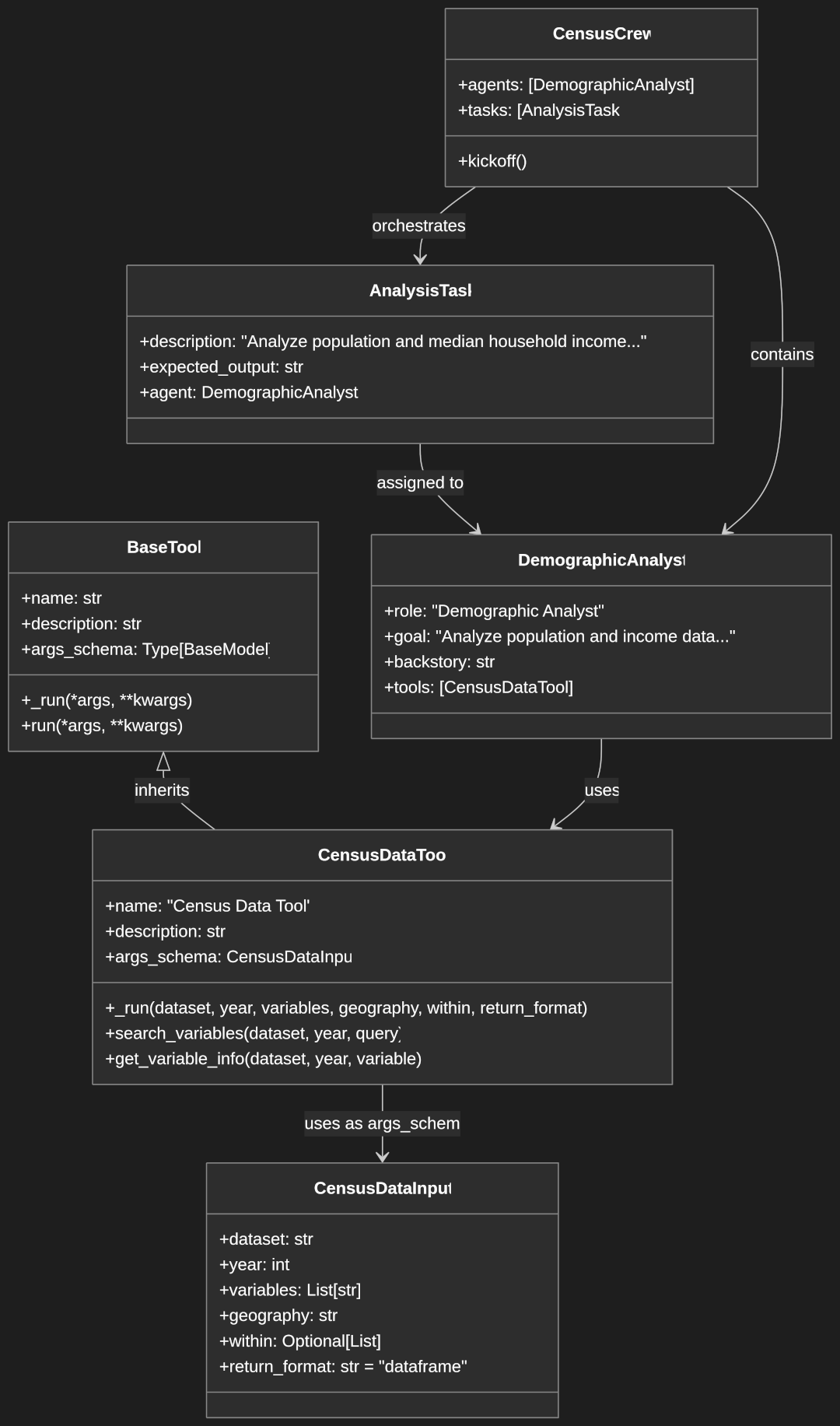
We next need to load and run the MoveNet model to detect poses in the video stream. We’ll encapsulate this functionality in a custom React hook called usePoseDetection:
src/hooks/usePoseDetection.ts:
import { useState, useEffect, useRef } from 'react';
import * as poseDetection from '@tensorflow-models/pose-detection';
import * as tf from '@tensorflow/tfjs';
export const usePoseDetection = () => {
const [detector, setDetector] = useState<poseDetection.PoseDetector | null>(null);
const [keypoints, setKeypoints] = useState<poseDetection.Keypoint[] | null>(null);
const [loading, setLoading] = useState(true);
const [error, setError] = useState<string | null>(null);
const [isActive, setIsActive] = useState(false);
const videoRef = useRef<HTMLVideoElement | null>(null);
const requestRef = useRef<number | null>(null);
// Initialize the pose detector
useEffect(() => {
const initializeDetector = async () => {
try {
console.log('Initializing TensorFlow...');
await tf.ready();
console.log('TensorFlow ready');
// Create detector using MoveNet model
const detectorConfig = {
modelType: poseDetection.movenet.modelType.SINGLEPOSE_LIGHTNING,
enableSmoothing: true
};
console.log('Creating pose detector...');
const detector = await poseDetection.createDetector(
poseDetection.SupportedModels.MoveNet,
detectorConfig
);
console.log('Pose detector created, setting state');
setDetector(detector);
setLoading(false);
} catch (e) {
console.error('Error initializing detector:', e);
setError(`Failed to initialize pose detector: ${e instanceof Error ? e.message : String(e)}`);
setLoading(false);
}
};
initializeDetector();
return () => {
if (requestRef.current) {
cancelAnimationFrame(requestRef.current);
}
};
}, []);
// Function to register video element
const registerVideo = (video: HTMLVideoElement) => {
console.log('Registering video element');
videoRef.current = video;
setIsActive(true);
};
// Function to stop detection and camera
const stopDetection = () => {
console.log('Stopping detection and camera');
setIsActive(false);
if (requestRef.current) {
cancelAnimationFrame(requestRef.current);
requestRef.current = null;
}
setKeypoints(null);
// Stop the camera stream
if (videoRef.current?.srcObject) {
const stream = videoRef.current.srcObject as MediaStream;
stream.getTracks().forEach(track => {
track.stop();
});
videoRef.current.srcObject = null;
}
videoRef.current = null;
};
// Start detection when both detector and video are available
useEffect(() => {
console.log('Checking detection prerequisites:', {
hasDetector: !!detector,
hasVideo: !!videoRef.current,
isActive
});
if (detector && videoRef.current && isActive) {
console.log('Both detector and video ready, starting detection');
detectPose();
}
}, [detector, isActive]);
// Main pose detection function using requestAnimationFrame for smooth updates
const detectPose = async () => {
if (!isActive) {
console.log('Detection stopped');
return;
}
if (detector && videoRef.current && videoRef.current.readyState === 4) {
try {
const poses = await detector.estimatePoses(
videoRef.current,
{ flipHorizontal: false }
);
if (poses.length > 0) {
console.log('Pose detected:', {
numKeypoints: poses[0].keypoints.length,
sampleKeypoint: poses[0].keypoints[0]
});
setKeypoints(poses[0].keypoints);
}
} catch (e) {
console.error('Error during pose detection:', e);
}
}
if (isActive) {
requestRef.current = requestAnimationFrame(detectPose);
}
};
return {
loading,
error,
keypoints,
registerVideo,
stopDetection
};
};
This hook is the heart of our pose detection system. Let’s examine its key components:
- State Management:
detector: Stores the initialized MoveNet pose detectorkeypoints: Stores the latest detected pose keypointsloading: Indicates whether the model is still loadingerror: Captures any errors during initialization or detectionisActive: Tracks whether pose detection is currently active
- TensorFlow.js Initialization:
- We call
tf.ready()to ensure TensorFlow.js is initialized - This prepares the WebGL backend and optimizes performance
- We call
- MoveNet Model Configuration:
- We use the “SINGLEPOSE_LIGHTNING” variant of MoveNet
- This variant prioritizes speed over accuracy, making it suitable for real-time applications
- We enable smoothing to reduce jitter in the detected keypoints
- Pose Detection Loop:
- We use
requestAnimationFramefor efficient, browser-optimized animation - In each frame, we call
detector.estimatePoses()to analyze the current video frame - The detector returns an array of poses, each containing keypoints with x, y coordinates and confidence scores
- We update our state with the detected keypoints
- We use
- Lifecycle Management:
- The
registerVideofunction connects our webcam component to the detection hook - The
stopDetectionfunction properly cleans up resources when detection is stopped - We cancel any pending animation frames and release the camera stream
- The
- Error Handling:
- We catch and report any errors during model initialization or detection
- This ensures our application remains stable even if the ML components encounter issues
This hook provides a clean API for other components to access pose detection functionality without needing to understand the complexities of TensorFlow.js or the MoveNet model.
The approach separates concerns effectively:
- The machine learning logic is isolated in this hook
- UI components can simply consume the detection results
- The detection loop runs efficiently using browser animation primitives
Visualizing Pose Detection Results
Detecting poses is only the first step; we also need to provide visual feedback to users. We’ll create a Canvas component that overlays the webcam feed and draws the detected pose keypoints and skeleton:
src/components/Canvas.tsx:
import { useEffect, useRef } from 'react';
import { Keypoint } from '@tensorflow-models/pose-detection';
import { drawKeypoints, drawSkeleton } from '../utils/drawUtils';
interface CanvasProps {
keypoints: Keypoint[] | null;
width: number;
height: number;
}
export const Canvas = ({ keypoints, width, height }: CanvasProps) => {
const canvasRef = useRef<HTMLCanvasElement>(null);
useEffect(() => {
if (canvasRef.current && keypoints) {
const ctx = canvasRef.current.getContext('2d');
if (ctx) {
ctx.clearRect(0, 0, width, height);
// Canvas is mirrored like the video
ctx.save();
ctx.scale(-1, 1);
ctx.translate(-width, 0);
// Draw the detected keypoints and skeleton
drawKeypoints(ctx, keypoints);
drawSkeleton(ctx, keypoints);
ctx.restore();
}
}
}, [keypoints, width, height]);
return (
<canvas
ref={canvasRef}
width={width}
height={height}
style={{
position: 'absolute',
top: 0,
left: 0
}}
/>
);
};
This Canvas component uses the HTML Canvas API to draw the visualization of detected poses. It:
- Creates a transparent overlay positioned on top of the webcam feed
- Updates on every new pose detection when the
keypointsprop changes - Mirrors the drawing to match the mirrored webcam feed
- Delegates the actual drawing to utility functions for better organization
Let’s look at those drawing utility functions:
src/utils/drawUtils.ts:
import { Keypoint } from '@tensorflow-models/pose-detection';
// Color constants for drawing
const color = 'aqua';
const lineWidth = 2;
const pointRadius = 4;
// MoveNet connects keypoints in this specific pattern to form a skeleton
const connectedKeypoints = [
['nose', 'left_eye'], ['nose', 'right_eye'],
['left_eye', 'left_ear'], ['right_eye', 'right_ear'],
['left_shoulder', 'right_shoulder'], ['left_shoulder', 'left_elbow'],
['right_shoulder', 'right_elbow'], ['left_elbow', 'left_wrist'],
['right_elbow', 'right_wrist'], ['left_shoulder', 'left_hip'],
['right_shoulder', 'right_hip'], ['left_hip', 'right_hip'],
['left_hip', 'left_knee'], ['right_hip', 'right_knee'],
['left_knee', 'left_ankle'], ['right_knee', 'right_ankle']
];
// Draw the detected keypoints
export const drawKeypoints = (ctx: CanvasRenderingContext2D, keypoints: Keypoint[]): void => {
keypoints.forEach(keypoint => {
// Only draw keypoints with a confidence greater than 0.3
if (keypoint.score && keypoint.score > 0.3) {
const { x, y } = keypoint;
ctx.beginPath();
ctx.arc(x, y, pointRadius, 0, 2 * Math.PI);
ctx.fillStyle = color;
ctx.fill();
}
});
};
// Draw the skeleton connecting keypoints
export const drawSkeleton = (ctx: CanvasRenderingContext2D, keypoints: Keypoint[]): void => {
// Create a map of keypoints by name for easier lookup
const keypointMap: Record<string, Keypoint> = {};
keypoints.forEach(keypoint => {
if (keypoint.name) {
keypointMap[keypoint.name] = keypoint;
}
});
ctx.strokeStyle = color;
ctx.lineWidth = lineWidth;
connectedKeypoints.forEach(([name1, name2]) => {
const keypoint1 = keypointMap[name1];
const keypoint2 = keypointMap[name2];
// Only draw if both keypoints exist and have good confidence
if (
keypoint1?.score && keypoint1.score > 0.3 &&
keypoint2?.score && keypoint2.score > 0.3
) {
ctx.beginPath();
ctx.moveTo(keypoint1.x, keypoint1.y);
ctx.lineTo(keypoint2.x, keypoint2.y);
ctx.stroke();
}
});
};
The drawing utilities create a visual representation of the detected pose by:
- Drawing keypoints as circles at each detected body part location
- Drawing a skeleton by connecting specific pairs of keypoints with lines
- Filtering by confidence to avoid showing inaccurate detections (threshold of 0.3)
The connectedKeypoints array defines which body parts should be connected in the skeleton visualization, creating a human-like stick figure. This pattern follows the anatomical structure that the MoveNet model is designed to detect.
Together, the Canvas component and drawing utilities provide immediate visual feedback to users, helping them understand how the model perceives their pose.
Implementing Gesture Detection Logic
From Pose Data to Meaningful Gestures
Now that we can detect poses, the next challenge is to interpret this raw data into meaningful gestures. Gesture detection involves analyzing the spatial relationships between body keypoints to identify specific postures. We’ll implement utility functions that transform raw keypoint data into higher-level gesture classifications:
src/utils/poseUtils.ts:
import { Keypoint } from '@tensorflow-models/pose-detection';
// Interface for a detected gesture
export interface DetectedGesture {
name: string;
confidence: number;
}
// Helper function to calculate the angle between three points
export const calculateAngle = (
firstPoint: Keypoint,
midPoint: Keypoint,
lastPoint: Keypoint
): number => {
if (!firstPoint || !midPoint || !lastPoint) return 0;
// Calculate vectors from midpoint to first and last points
const v1 = {
x: firstPoint.x - midPoint.x,
y: firstPoint.y - midPoint.y
};
const v2 = {
x: lastPoint.x - midPoint.x,
y: lastPoint.y - midPoint.y
};
// Calculate dot product
const dotProduct = v1.x * v2.x + v1.y * v2.y;
// Calculate magnitudes
const v1Magnitude = Math.sqrt(v1.x * v1.x + v1.y * v1.y);
const v2Magnitude = Math.sqrt(v2.x * v2.x + v2.y * v2.y);
// Calculate angle in radians
const angleRad = Math.acos(dotProduct / (v1Magnitude * v2Magnitude));
// Convert to degrees
return (angleRad * 180) / Math.PI;
};
// Helper to get keypoints by name from the keypoints array
export const getKeypointByName = (
keypoints: Keypoint[],
name: string
): Keypoint | undefined => {
return keypoints.find(keypoint => keypoint.name === name);
};
// Function to check if a point is above another point
export const isAbove = (point1: Keypoint, point2: Keypoint): boolean => {
return point1.y < point2.y;
};
// Function to check if a point is to the left of another point
export const isLeftOf = (point1: Keypoint, point2: Keypoint): boolean => {
return point1.x < point2.x;
};
// Check if a keypoint has sufficient confidence score
export const hasConfidence = (keypoint: Keypoint | undefined, threshold = 0.3): boolean => {
return !!keypoint && !!keypoint.score && keypoint.score > threshold;
};
// Function to check multiple keypoints have sufficient confidence
export const allHaveConfidence = (keypoints: (Keypoint | undefined)[], threshold = 0.3): boolean => {
return keypoints.every(keypoint => hasConfidence(keypoint, threshold));
};
These utility functions provide the building blocks for our gesture detection system:
calculateAngle: Uses vector mathematics to find the angle formed by three keypoints, which is essential for detecting joint angles (like elbows and knees)getKeypointByName: Retrieves a specific keypoint (like “left_wrist”) from the array of detected keypointsisAboveandisLeftOf: Simple spatial relationship checkshasConfidenceandallHaveConfidence: Filter out unreliable detections based on the model’s confidence scores
With these utilities in place, we can implement specific gesture detectors:
src/utils/gestureDetection.ts:
import { Keypoint } from '@tensorflow-models/pose-detection';
import {
calculateAngle,
getKeypointByName,
isAbove,
isLeftOf,
hasConfidence,
allHaveConfidence,
DetectedGesture
} from './poseUtils';
// Detect if arms are raised (both hands above shoulders)
export const detectRaisedHands = (keypoints: Keypoint[]): DetectedGesture | null => {
const leftShoulder = getKeypointByName(keypoints, 'left_shoulder');
const rightShoulder = getKeypointByName(keypoints, 'right_shoulder');
const leftWrist = getKeypointByName(keypoints, 'left_wrist');
const rightWrist = getKeypointByName(keypoints, 'right_wrist');
if (
allHaveConfidence([leftShoulder, rightShoulder, leftWrist, rightWrist])
) {
const leftHandRaised = isAbove(leftWrist!, leftShoulder!);
const rightHandRaised = isAbove(rightWrist!, rightShoulder!);
if (leftHandRaised && rightHandRaised) {
// Calculate confidence as average of relevant keypoint scores
const confidence = [leftShoulder, rightShoulder, leftWrist, rightWrist]
.reduce((sum, keypoint) => sum + (keypoint?.score || 0), 0) / 4;
return {
name: 'raised_hands',
confidence
};
}
}
return null;
};
// Detect T-pose (arms extended horizontally)
export const detectTPose = (keypoints: Keypoint[]): DetectedGesture | null => {
const leftShoulder = getKeypointByName(keypoints, 'left_shoulder');
const rightShoulder = getKeypointByName(keypoints, 'right_shoulder');
const leftElbow = getKeypointByName(keypoints, 'left_elbow');
const rightElbow = getKeypointByName(keypoints, 'right_elbow');
const leftWrist = getKeypointByName(keypoints, 'left_wrist');
const rightWrist = getKeypointByName(keypoints, 'right_wrist');
if (!allHaveConfidence([leftShoulder, rightShoulder, leftElbow, rightElbow, leftWrist, rightWrist], 0.2)) {
return null;
}
// Check if arms are extended horizontally
const leftArmAngle = calculateAngle(leftShoulder!, leftElbow!, leftWrist!);
const rightArmAngle = calculateAngle(rightShoulder!, rightElbow!, rightWrist!);
// Arms should be relatively straight (angle close to 180 degrees)
const armsExtended = leftArmAngle > 160 && rightArmAngle > 160;
// Check if wrists are roughly at shoulder height
const leftWristAtShoulderHeight = Math.abs(leftWrist!.y - leftShoulder!.y) < 30;
const rightWristAtShoulderHeight = Math.abs(rightWrist!.y - rightShoulder!.y) < 30;
if (armsExtended && leftWristAtShoulderHeight && rightWristAtShoulderHeight) {
const confidence = [leftShoulder, rightShoulder, leftElbow, rightElbow, leftWrist, rightWrist]
.reduce((sum, keypoint) => sum + (keypoint?.score || 0), 0) / 6;
return {
name: 't_pose',
confidence
};
}
return null;
};
// Detect pointing right (right arm extended to the right)
export const detectPointingRight = (keypoints: Keypoint[]): DetectedGesture | null => {
const leftShoulder = getKeypointByName(keypoints, 'left_shoulder');
const rightShoulder = getKeypointByName(keypoints, 'right_shoulder');
const leftElbow = getKeypointByName(keypoints, 'left_elbow');
const rightElbow = getKeypointByName(keypoints, 'right_elbow');
const leftWrist = getKeypointByName(keypoints, 'left_wrist');
const rightWrist = getKeypointByName(keypoints, 'right_wrist');
if (!allHaveConfidence([rightShoulder, rightElbow, rightWrist], 0.25)) {
return null;
}
const rightArmAngle = calculateAngle(rightShoulder!, rightElbow!, rightWrist!);
const isRightArmExtended = rightArmAngle > 150;
// Since webcam is mirrored, "pointing right" means wrist is to the left of elbow
const isPointingRight = isLeftOf(rightWrist!, rightElbow!);
// Check that left arm is not extended
const leftArmAngle = calculateAngle(leftShoulder!, leftElbow!, leftWrist!);
const isLeftArmRelaxed = leftArmAngle < 120;
console.log('Right pointing detection (mirrored):', {
rightArmAngle,
isRightArmExtended,
isPointingRight,
isLeftArmRelaxed,
rightElbowX: rightElbow!.x,
rightWristX: rightWrist!.x
});
if (isRightArmExtended && isPointingRight && isLeftArmRelaxed) {
const confidence = [rightShoulder, rightElbow, rightWrist]
.reduce((sum, keypoint) => sum + (keypoint?.score || 0), 0) / 3;
return {
name: 'pointing_right',
confidence
};
}
return null;
};
// Detect pointing left (left arm extended to the left)
export const detectPointingLeft = (keypoints: Keypoint[]): DetectedGesture | null => {
const leftShoulder = getKeypointByName(keypoints, 'left_shoulder');
const rightShoulder = getKeypointByName(keypoints, 'right_shoulder');
const leftElbow = getKeypointByName(keypoints, 'left_elbow');
const rightElbow = getKeypointByName(keypoints, 'right_elbow');
const leftWrist = getKeypointByName(keypoints, 'left_wrist');
const rightWrist = getKeypointByName(keypoints, 'right_wrist');
if (!allHaveConfidence([leftShoulder, leftElbow, leftWrist], 0.25)) {
return null;
}
const leftArmAngle = calculateAngle(leftShoulder!, leftElbow!, leftWrist!);
const isLeftArmExtended = leftArmAngle > 150;
// Since webcam is mirrored, "pointing left" means wrist is to the right of elbow
const isPointingLeft = isLeftOf(leftElbow!, leftWrist!);
// Check that right arm is not extended
const rightArmAngle = calculateAngle(rightShoulder!, rightElbow!, rightWrist!);
const isRightArmRelaxed = rightArmAngle < 120;
console.log('Left pointing detection (mirrored):', {
leftArmAngle,
isLeftArmExtended,
isPointingLeft,
isRightArmRelaxed,
leftElbowX: leftElbow!.x,
leftWristX: leftWrist!.x
});
if (isLeftArmExtended && isPointingLeft && isRightArmRelaxed) {
const confidence = [leftShoulder, leftElbow, leftWrist]
.reduce((sum, keypoint) => sum + (keypoint?.score || 0), 0) / 3;
return {
name: 'pointing_left',
confidence
};
}
return null;
};
// Main function to detect all gestures
export const detectGestures = (keypoints: Keypoint[] | null): DetectedGesture[] => {
if (!keypoints || keypoints.length === 0) {
return [];
}
const gestureDetectors = [
detectRaisedHands,
detectTPose,
detectPointingRight,
detectPointingLeft
];
const detectedGestures = gestureDetectors
.map(detector => detector(keypoints))
.filter((gesture): gesture is DetectedGesture => gesture !== null);
return detectedGestures;
};
Each gesture detector follows a similar pattern:
- Retrieve relevant keypoints for the gesture (like shoulders and wrists for raised hands)
- Check confidence thresholds to ensure reliable detection
- Apply geometric rules specific to the gesture (like “hands above shoulders”)
- Calculate a confidence score for the gesture based on the keypoints involved
- Return a named gesture or null if the gesture isn’t detected
The main detectGestures function runs all gesture detectors and combines their results into a single array of detected gestures.
To make this functionality accessible to our React components, we’ll create a custom hook:
src/hooks/useGestureDetection.ts:
import { useState, useEffect } from 'react';
import { Keypoint } from '@tensorflow-models/pose-detection';
import { detectGestures, DetectedGesture } from '../utils/gestureDetection';
export const useGestureDetection = (keypoints: Keypoint[] | null) => {
const [gestures, setGestures] = useState<DetectedGesture[]>([]);
useEffect(() => {
if (keypoints) {
// Detect gestures based on the latest keypoints
const detectedGestures = detectGestures(keypoints);
setGestures(detectedGestures);
} else {
setGestures([]);
}
}, [keypoints]);
return { gestures };
};This hook encapsulates the gesture detection logic and provides an easy-to-use interface for components to access detected gestures. It updates the gestures whenever new keypoints are detected, ensuring real-time gesture recognition.
You can easily add new gesture detectors by following the same pattern. For example, you could implement detectors for different positions by defining the appropriate geometric relationships between keypoints.
Remaining Components
We have a few remaining components to build and we need to include it into our App.tsx. First we need to combine our WebcamComponent and Canvas as well as display the detection information.
src/components/PoseDetector.tsx
import { useState } from 'react';
import { WebcamComponent } from './WebcamComponent';
import { Canvas } from './Canvas';
import { GestureControlledElement } from './GestureControlledElement';
import { usePoseDetection } from '../hooks/usePoseDetection';
import { useGestureDetection } from '../hooks/useGestureDetection';
interface PoseDetectorProps {
onStop: () => void;
}
export const PoseDetector = ({ onStop }: PoseDetectorProps) => {
const [dimensions] = useState({ width: 640, height: 480 });
const { loading, error, keypoints, registerVideo, stopDetection } = usePoseDetection();
const { gestures } = useGestureDetection(keypoints);
const handleStop = () => {
stopDetection();
onStop();
};
return (
<div className="pose-detector">
{loading && <div className="loading">Loading pose detection model...</div>}
{error && <div className="error">{error}</div>}
<div className="webcam-container" style={{ position: 'relative', width: dimensions.width, height: dimensions.height }}>
<WebcamComponent
onVideoReady={registerVideo}
width={dimensions.width}
height={dimensions.height}
/>
{keypoints && (
<Canvas
keypoints={keypoints}
width={dimensions.width}
height={dimensions.height}
/>
)}
</div>
<div className="controls">
<button onClick={handleStop} className="stop-button">
Stop Detection
</button>
</div>
{keypoints && (
<GestureControlledElement gestures={gestures} />
)}
<div className="detection-info">
<div className="gesture-list">
<h3>Detected Gestures</h3>
{gestures.length > 0 ? (
<ul>
{gestures.map((gesture, index) => (
<li key={index}>
{gesture.name.replace('_', ' ')}
(confidence: {gesture.confidence.toFixed(2)})
</li>
))}
</ul>
) : (
<p>No gestures detected</p>
)}
</div>
<div className="pose-data">
<h3>Detected Pose Keypoints</h3>
<pre>{JSON.stringify(keypoints?.slice(0, 3), null, 2)}...</pre>
</div>
</div>
</div>
);
};
This component displays our child components and handles stopping the detection. Now let’s create a component to display gesture data and provide feedback to the user. We’ll move a circle around an area in relation to pose detection.
import { useState, useEffect } from 'react';
import { DetectedGesture } from '../utils/poseUtils';
interface GestureControlledElementProps {
gestures: DetectedGesture[];
}
export const GestureControlledElement = ({ gestures }: GestureControlledElementProps) => {
const [position, setPosition] = useState({ x: 50, y: 50 });
const [color, setColor] = useState('#3f51b5');
// Get the first detected gesture with highest confidence
const primaryGesture = gestures.length > 0
? gestures.reduce((prev, current) =>
(current.confidence > prev.confidence) ? current : prev)
: null;
useEffect(() => {
// Update position or appearance based on detected gesture
if (primaryGesture) {
switch (primaryGesture.name) {
case 'pointing_right':
setPosition(prev => ({ ...prev, x: Math.min(90, prev.x + 5) }));
setColor('#4caf50'); // Green
break;
case 'pointing_left':
setPosition(prev => ({ ...prev, x: Math.max(10, prev.x - 5) }));
setColor('#2196f3'); // Blue
break;
case 'raised_hands':
setPosition(prev => ({ ...prev, y: Math.max(10, prev.y - 5) }));
setColor('#ff9800'); // Orange
break;
case 't_pose':
setPosition(prev => ({ ...prev, y: Math.min(90, prev.y + 5) }));
setColor('#e91e63'); // Pink
break;
default:
// No recognized gesture
setColor('#3f51b5'); // Default purple
}
}
}, [primaryGesture]);
return (
<div className="gesture-controlled-container">
<div className="gesture-indicator">
{primaryGesture ? (
<p>Detected: <strong>{primaryGesture.name.replace('_', ' ')}</strong></p>
) : (
<p>No gesture detected</p>
)}
</div>
<div className="gesture-playground">
<div
className="controlled-element"
style={{
left: `${position.x}%`,
top: `${position.y}%`,
backgroundColor: color,
transition: 'all 0.2s ease-out'
}}
/>
</div>
</div>
);
};Sets the color of the circle and moves in in the appropriate direction during gesture detection. Now let’s update our main application files to link everything together.
src/App.tsx
import { useState } from 'react';
import { PoseDetector } from './components/PoseDetector';
import './App.css';
function App() {
const [showDetector, setShowDetector] = useState(false);
const handleStart = () => {
setShowDetector(true);
};
const handleStop = () => {
setShowDetector(false);
};
return (
<div className="app">
<header>
<h1>TensorFlow.js Pose Detection</h1>
<p>Real-time gesture control using TensorFlow.js and MoveNet</p>
</header>
<main>
{!showDetector ? (
<div className="start-section">
<p>
This application uses your webcam to detect body poses and gestures in real-time.
All processing happens directly in your browser - no data is sent to any server.
</p>
<div className="instructions">
<h2>Supported Gestures:</h2>
<ul>
<li>
<strong>Raise both hands</strong> - Move the ball upward
</li>
<li>
<strong>T-pose</strong> (arms extended horizontally) - Move the ball downward
</li>
<li>
<strong>Point right</strong> (right arm extended) - Move the ball to the right
</li>
<li>
<strong>Point left</strong> (left arm extended) - Move the ball to the left
</li>
</ul>
</div>
<button onClick={handleStart}>
Start Pose Detection
</button>
</div>
) : (
<div>
<PoseDetector onStop={handleStop} />
</div>
)}
</main>
<footer>
<p>
Built with React, TypeScript, and TensorFlow.js
</p>
</footer>
</div>
);
}
export default App;
And let’s add some styling by updating the stylesheet.
src/App.css
.app {
max-width: 1200px;
margin: 0 auto;
padding: 20px;
font-family: system-ui, -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto,
'Helvetica Neue', Arial, sans-serif;
}
header {
text-align: center;
margin-bottom: 30px;
}
header h1 {
color: #3f51b5;
margin-bottom: 10px;
}
main {
display: flex;
flex-direction: column;
align-items: center;
}
.start-section {
max-width: 600px;
text-align: center;
margin-bottom: 30px;
}
.start-section button {
background-color: #3f51b5;
color: white;
border: none;
padding: 12px 24px;
font-size: 16px;
border-radius: 4px;
cursor: pointer;
transition: background-color 0.2s;
}
.start-section button:hover {
background-color: #303f9f;
}
.pose-detector {
display: flex;
flex-direction: column;
align-items: center;
}
.loading, .error {
margin: 20px 0;
padding: 10px;
border-radius: 4px;
text-align: center;
}
.loading {
background-color: #e3f2fd;
color: #0d47a1;
}
.error {
background-color: #ffebee;
color: #c62828;
}
.webcam-container {
border: 2px solid #3f51b5;
border-radius: 4px;
overflow: hidden;
}
.pose-data {
margin-top: 20px;
width: 100%;
max-width: 640px;
}
.pose-data pre {
background-color: #f5f5f5;
padding: 10px;
border-radius: 4px;
overflow-x: auto;
}
footer {
margin-top: 40px;
text-align: center;
color: #666;
font-size: 14px;
}
.gesture-controlled-container {
margin-top: 30px;
width: 100%;
max-width: 640px;
}
.gesture-indicator {
background-color: #f5f5f5;
padding: 10px;
border-radius: 4px;
text-align: center;
margin-bottom: 15px;
}
.gesture-playground {
position: relative;
width: 100%;
height: 300px;
background-color: #f0f0f0;
border-radius: 4px;
overflow: hidden;
}
.controlled-element {
position: absolute;
width: 50px;
height: 50px;
border-radius: 50%;
transform: translate(-50%, -50%);
box-shadow: 0 2px 10px rgba(0, 0, 0, 0.2);
}
.controls {
margin: 15px 0;
}
.stop-button {
background-color: #f44336;
color: white;
border: none;
padding: 10px 20px;
font-size: 16px;
border-radius: 4px;
cursor: pointer;
transition: background-color 0.2s;
}
.stop-button:hover {
background-color: #d32f2f;
}
.detection-info {
display: flex;
flex-direction: column;
width: 100%;
max-width: 640px;
gap: 20px;
}
.gesture-list {
background-color: #f5f5f5;
padding: 15px;
border-radius: 4px;
}
.gesture-list ul {
list-style: none;
padding: 0;
}
.gesture-list li {
padding: 8px 0;
border-bottom: 1px solid #e0e0e0;
}
.gesture-list li:last-child {
border-bottom: none;
}
.instructions {
background-color: #e8eaf6;
padding: 20px;
border-radius: 4px;
margin: 20px 0;
text-align: left;
}
.instructions h2 {
margin-top: 0;
color: #3f51b5;
}
.instructions ul {
padding-left: 20px;
}
.instructions li {
margin-bottom: 10px;
}Running The Pose Detection Application
Now let’s start our application.
npm run dev
Conclusion
This tutorial has demonstrated how TensorFlow.js enables sophisticated machine learning directly in the browser. We’ve built a complete pose detection application that captures webcam input, processes it through the MoveNet model, and translates body movements into meaningful gestures—all running locally in the user’s browser.
Our implementation showcases the core strengths of browser-based ML: enhanced privacy as data never leaves the user’s device, improved accessibility without specialized hardware requirements, and responsive interaction through WebGL-accelerated processing. By combining modern web technologies with pre-trained ML models, we’ve created an application that would have required custom hardware and server infrastructure just a few years ago.
The patterns we’ve explored—from accessing device cameras to interpreting pose data—can be extended to various applications including fitness tracking, interactive games, and accessibility tools. As TensorFlow.js continues to evolve, the barrier to entry for implementing ML-powered experiences will continue to lower, enabling more developers to build intelligent, responsive applications that respect user privacy.